-
-
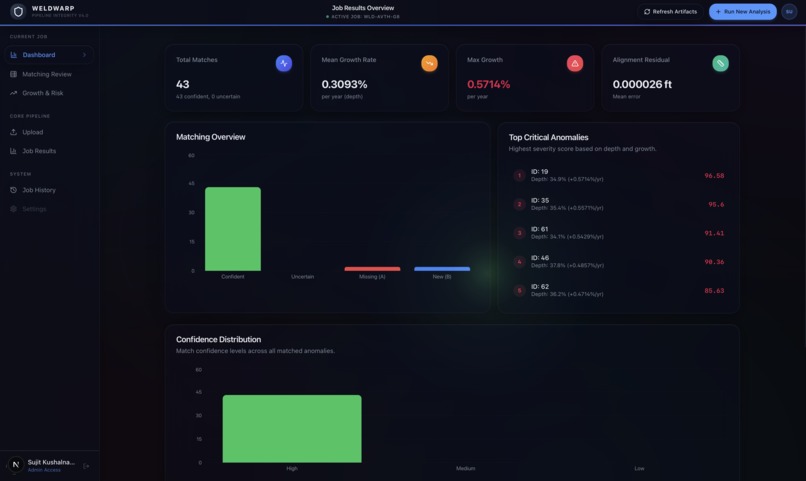
Dashboard
-
OAuth
-
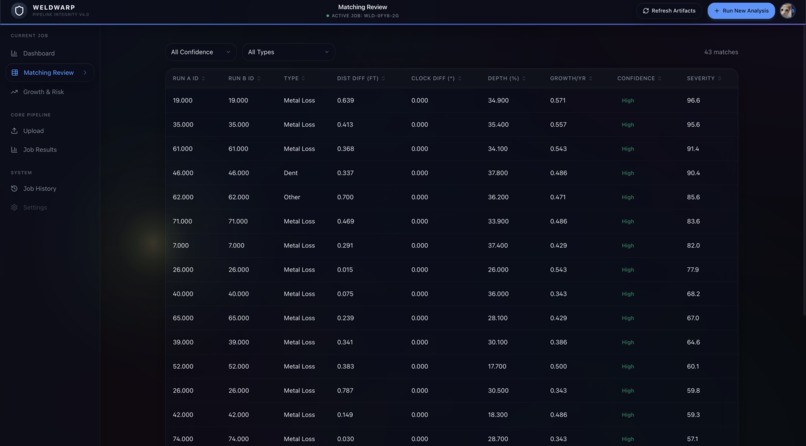
Matching Review
-
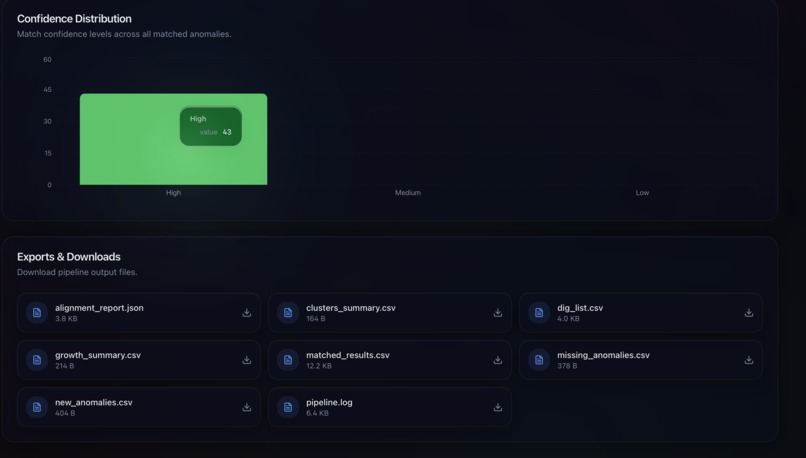
CSV Files to get
-
Upload Files
-
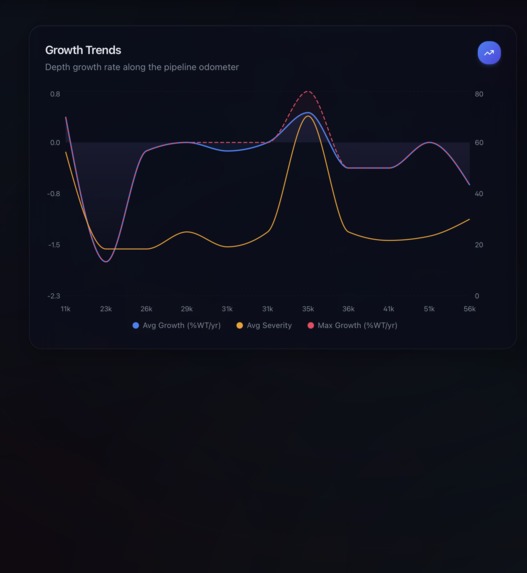
Growth Trends Graph
-
Job History







Inspiration
ILI data is high-stakes but messy. Different vendors use different column names and units, and odometer drift makes the same weld or defect land at different reported distances across runs. Even when the physics is simple, the workflow becomes spreadsheet-heavy: lining up runs, guessing which anomalies correspond, and then defending growth rates and dig priorities.
WeldWarp came from wanting a repeatable, defensible process: align multi-run ILI datasets using fixed landmarks, match anomalies with a globally optimal method, quantify uncertainty, and produce outputs that are fast to review and easy to share.
What it does
WeldWarp takes two or more ILI runs and turns them into a single integrity story.
- Ingest + normalize vendor files (Excel/CSV) into a canonical schema so all runs are comparable
- Align runs using fixed control points (girth welds, valves, tees) to correct odometer drift
- Match anomalies within each aligned segment using candidate gating + the Hungarian algorithm
- Score match quality with a Gaussian likelihood and a sigmoid confidence score
- Compute integrity metrics: growth rates, remaining life, severity ranking, and a dig list
- Optional analytics: DBSCAN clustering, multi-run forecasting with AIC/BIC model selection
- Deliver results via CLI and a secure web dashboard (OAuth + role-based access), with exports (CSV/JSON/HTML)
How we built it
We built WeldWarp as a modular Python pipeline with a web app layered on top, so the same core algorithms run from the CLI or the dashboard.
Pipeline (Python)
Ingestion + auto-mapping We read Excel/CSV, score known vendor configs against headers, pick the best mapping, then normalize into a canonical schema: distance, clock_deg, depth_percent, type, orientation, length, width, wall_thickness. If mapping confidence is low, we fall back to fuzzy substring detection.
Key math
Clock distance (circular)
$$ D = |A - B| \bmod 360 $$ $$ C = \min(D,\ 360 - D) $$
Piecewise linear alignment (odometer drift)
$$ s = \frac{A1 - A0}{B1 - B0} $$ $$ t = A0 - s\cdot B0 $$ $$ x' = s\cdot x + t $$
Matching cost (candidate score)
$$ cost = wd\cdot |dd| + wc\cdot |dc| + wp\cdot |dp| + ws\cdot ds + p $$
One-to-one optimal matching (Hungarian goal)
$$ \min \sum_i cost(i,\ m(i)) $$
Match likelihood (Gaussian-style)
$$ E = \left(\frac{dd}{sd}\right)^2 + \left(\frac{dc}{sc}\right)^2 + \left(\frac{dp}{sp}\right)^2 $$ $$ P = \exp(-E) $$
Growth rate (two runs)
$$ g = \frac{depth2 - depth1}{T} $$
Remaining life (to critical depth)
$$ life = \frac{crit - depth2}{g} $$
Severity score (ranking)
$$ norm(x) = \frac{x - xmin}{xmax - xmin} $$ $$ sev = 100\cdot \left(0.40\cdot norm(g) + 0.35\cdot norm(depth2) + 0.25\cdot norm(1/life)\right) $$
Web application
- Backend: FastAPI handles uploads, runs pipeline jobs asynchronously, tracks status, stores results, and enforces permissions.
- Frontend: Next.js provides drag-and-drop upload, sheet selection, dashboards, match review tables, and exports.
- OAuth + RBAC: Google/GitHub sign-in plus Admin/Engineer/Viewer roles with job ownership and sharing.
Challenges we ran into
- Vendor schema and unit inconsistencies required robust auto-mapping and safe fallbacks.
- Alignment needed to handle sparse control points and still produce quality metrics (residuals).
- Dense anomaly regions created ambiguous candidates, so confidence needed margin and density terms.
- Turning correct math into an engineer-friendly workflow required strong review UI and exports.
Accomplishments that we're proud of
- End-to-end automation from raw files to aligned matches, growth, severity, and dig list.
- Globally optimal one-to-one matching per segment via Hungarian assignment.
- Confidence scoring that surfaces ambiguity instead of hiding it.
- A secure web app (OAuth + RBAC) with job ownership, sharing, and downloadable reports.
What we learned
- Classical optimization and careful preprocessing can be very strong for multi-run ILI.
- Quantifying uncertainty is essential for trust and review.
- Usability, exports, and access control are part of the integrity solution, not just polish.
What's next for WeldWarp
- Calibrate \(sigma\), tolerances, and weights using labeled review data.
- Add a lightweight supervised validator/re-ranker to reduce edge-case mismatches.
- Expand vendor templates and add domain constraints (repairs, joint continuity checks).
- Harden for deployment: persistent storage, audit logs, containerized setup.
Log in or sign up for Devpost to join the conversation.