-
-
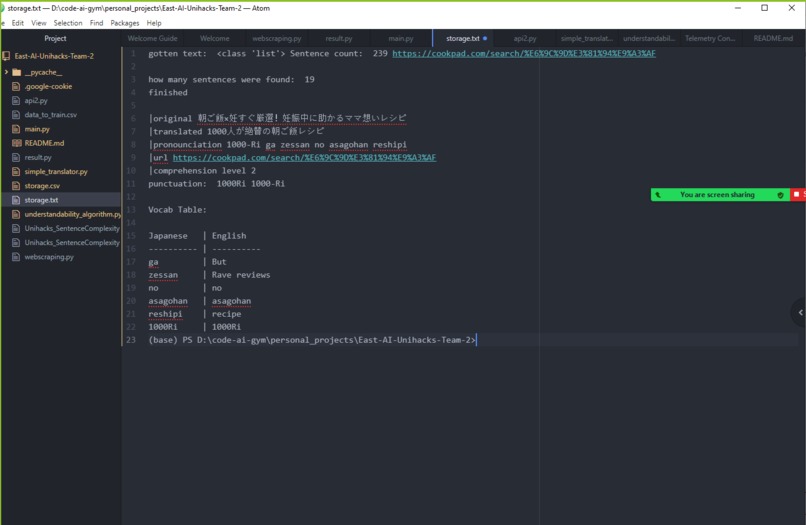
output from the demo pasted into a .txt so that the Japanese renders

Inspiration
Each of our group members have struggled with a foreign language themselves especially understanding context and semantics. Speaking the language was our greatest struggle, natural native context is overlooked by many language curriculums or the resources are limited and insufficient. For example the Spanish curriculum at East Chapel Hill High School assumes after 2 years of Spanish education that students no longer need as much speech training or vocabulary expansion. Spanish III and Spanish IV are spent researching the history of foreign countries, doing art history projects about Spanish artists, and only 3-5 minutes per class making a half-hearted attempt to speak to each other about our weekend. The attempts teachers make towards cultural immersion are largely ineffective with research of latin American history a favorite among the faculty. As proven by East Chapel Hill teachers can provide a website in Spanish for students to study but, that is just one example attempting to represent an entire culture; something that is impossible to do with limited resources. We recognized the internet as a boundless resource of cultural immersion where native speakers of every language and culture interact. Seeing the opportunity and that no one was attempting to harness its power we decided to pioneer a new age of culturally relevant language learning and full immersion into other cultures.
What problem does your project solve?
Many foreign language students around the world have difficulty with foreign language learning. This is primarily due to the inaccessibility of culturally relevant learning materials. Seeing that many people do not have access to overpriced membership plans and don’t have the ability to travel abroad, especially during the COVID-19 pandemic, there is a need for a project like ours. Foreign language classes also do not focus enough on context and immersion and resources and are far too limited when they do. This creates a deficiency in students comprehension harming their ability to speak the language itself but also to make sense of the complicated and rich culture behind it.
How does your project solve the problem?
Our project solves this problem through 3 key features. The first is our web scraper which takes user input of words, sentences, or paragraphs and scours the internet for websites containing sentences using those words. The scraper then displays the sentences and their origin websites so the user can not only read the sentence but also explore the entire website. The second is our adaptive artificial intelligence algorithm which limits the length and complexity of the sentences the web scraper searches for based on the knowledge level of the user. Through mechanisms such as syllable, character, and word count it assigns a level to a sentence learning over time what the user is most comfortable with. Assigning an overall web page readability score it adjusts the output in order to accommodate the user and ensure they can understand not just the sentence but also the overall website. Finally it translates the sentences organizing important information into a vocabulary list so the user can piece together which words they have trouble understanding through seeing their order and meaning within natural native context.
What technologies did your project use? Include programming languages, libraries, and any external tools.
Our project is entirely written in Python. Translation is achieved through the foremost accurate translation API: Google Translate. In order to create the web scraping ability we used the Selenium Webdriver API, BeautifulSoup library, google search, chrome options, and the requests library. Display organization was achieved with the Comma-separated values (csv) module and the Regular Expression Syntax module.
For the machine learning model, we used sklearn, for processing we used NLTK, and we used Matplotlib with Seaborn for visualization.
What challenges did you run into? The development of the webscraper was a big challenge. The selenium webscraper outputed sentences with large amounts of spaces and put words with hyperlinks on different lines. In order to ensure that all sentences are captured correctly and ignore one word sentences. We had to mess with regex and spent several hours on the formatting, obtaining help from some of the advisors.
To showcase how our app can bring culture and language together, we chose Japanese to make the cultural contrast more obvious-- and thus the value of the project. However, Japanese does not have spaces between words with made webscraping formatting, vocab separation and translation, as well as complexity detection exceedingly hard. We were eventually able to come up with a way to separate it into words by converting it into a word separated version of Japanese called romaji.
During the training of the machine learning model, we had to acquire training data. Without which the machine learning algorithm struggled to produce any results. After we completed our webscraping setup, we were able to scrape sentences from the internet, and assign difficulty levels to each of these sentences.
This is our full detailed business plan that expands on our business pitch: https://docs.google.com/document/d/1zlH5eHHgFswXNXHWxLkwrnkmTBDcp4YWbDH6lpCAxnU/edit?usp=sharing
Thank you so much for taking the time to look at our project!
Built With
- ajexapi
- beautiful-soup
- csv
- python
- regex
- requests
- selenium

Log in or sign up for Devpost to join the conversation.