-
-
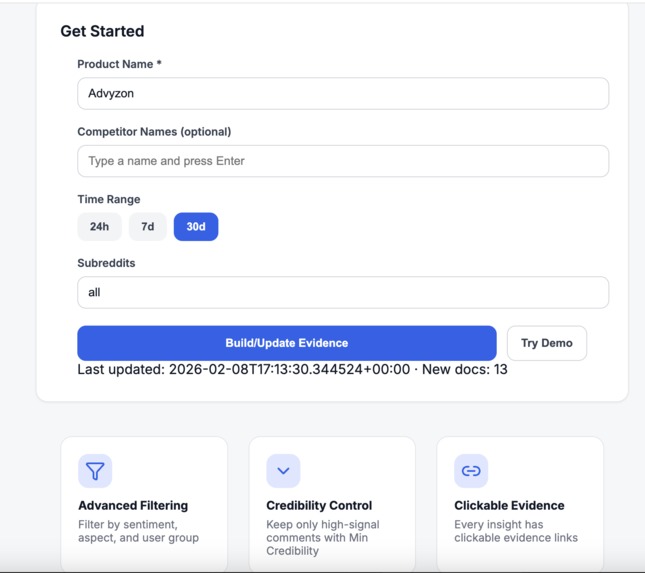
Setup page
-
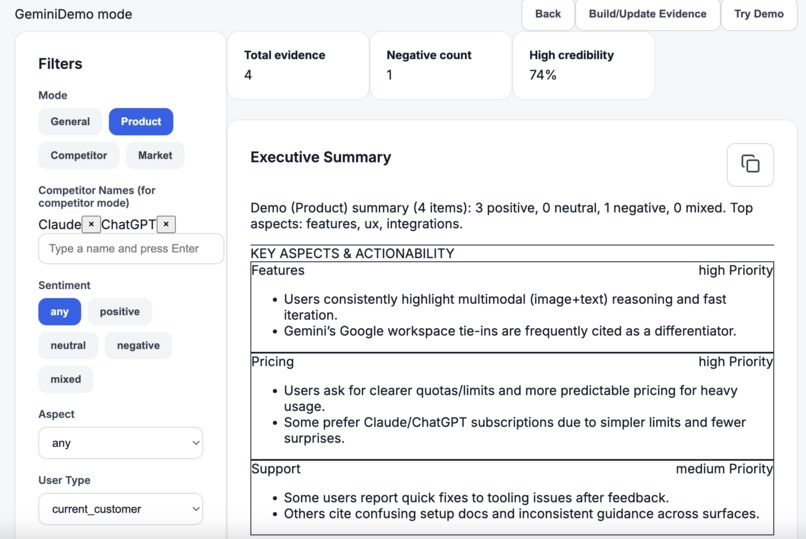
Insight Dashboard


About the project
Inspiration
As product builders, we kept running into the same problem: Reddit has honest, high-signal user feedback, but it’s painful to turn hundreds of threads and comments into actionable product decisions. We wanted something that could answer questions like “What’s actually broken?”, “What do users love and why?”, “How do we compare to competitors?”, and “What’s the market narrative?”—with clickable evidence, not vibes.
What we learned
- Evidence-first beats “pretty summaries.” A dashboard is only trustworthy when every insight can be traced back to real comments.
- LLM reliability is an engineering problem, not just a prompt problem. Rate limits, model availability differences, and serverless cold starts can make a “working” LLM integration fail in production unless you design for it.
- Mode matters. “Product feedback,” “competitor comparison,” and “market discussion” are different lenses; they need different relevance filters and different summaries to avoid mixing signals.
A simple way to think about “trust” in an insight is:
[ \text{Insight Trust} \approx \frac{\text{Evidence Coverage} \times \text{Specificity}}{\text{Noise} + \epsilon} ]
Where higher evidence coverage and specificity improve trust, while higher noise reduces it.
How we built it
- Frontend (Next.js + React + Tailwind): A dashboard UI to ingest data, switch modes (General / Product / Competitor / Market), apply filters (sentiment, aspect, user type, min credibility), and render a Markdown executive summary.
- Backend (FastAPI):
- Ingests Reddit/RSS content and stores it in SQLite.
- Uses Gemini to do LLM-based relevance filtering per mode (keep only comments that match Product vs Competitor vs Market intent).
- Generates an executive summary + aspect-level action items, grounded strictly in the retrieved comments.
- Deployment (Vercel): Hosted frontend + serverless FastAPI API routes, with environment variables for keys.
Challenges we faced (and how we addressed them)
- 429 TooManyRequests & quotas: Embedding-based RAG can explode API request volume during ingestion. We redesigned the pipeline to avoid embedding-heavy flows under tight free-tier limits and made LLM calls bounded and batched.
- Model availability issues (404 / unsupported models): Some model names differ across API versions and accounts. We implemented model discovery and safe fallback so the system selects an actually available generation model.
- Trust & hallucinations: We strengthened prompts and logic to enforce “grounded in evidence only” behavior, and we surface LLM vs fallback status in the UI so users always know what happened.
- Mode switching consistency: We ensured that switching modes triggers a fresh query so summaries and evidence actually change (not just the label).
What we’re proud of
This is a practical, demo-ready “Voice of Customer” system: it turns noisy Reddit discussions into mode-specific, evidence-backed insights that a PM can use immediately—without losing traceability.
Built With
- fastapi
- figma
- gemini-api
- http
- next.js
- python
- react
- reddit-rss
- sqlite
- tailwind-css
- typescript
- uvicorn
- vercel
Log in or sign up for Devpost to join the conversation.