-
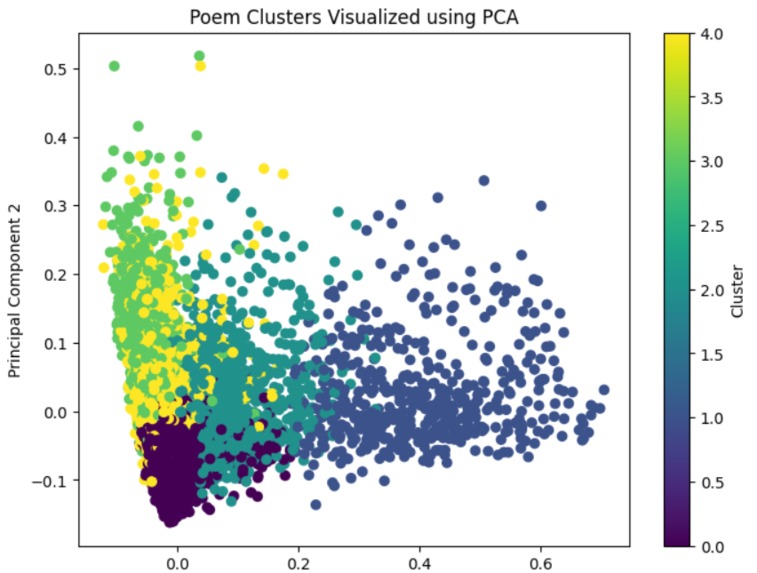
the five clusters of poetry

Inspiration
Poetry is a purely subjective art form, shaped by emotion, language, and individual expression. However, beneath its creative surface lie measurable patterns related to structure, length, and emotional intensity. With the increasing availability of large textual datasets, data analytics offers new ways to explore even human emotions.
The inspiration behind Verse Vectors was to explore the intersection of art and machine learning: Can unsupervised algorithms detect thematic similarities between poems without being explicitly told what those themes are?
What it does
Verse Vectors is a data analytics project that examines poetry through numerical representations derived from textual and emotional features. Using an existing poetry dataset sourced from Kaggle, this project transforms selected attributes—such as poem length, word structure, and emotional indicators—into numerical vectors. These vectors are then analyzed to uncover trends, distributions, and relationships within poetic expression.
The goal of this project is not to reduce poetry to numbers, but to demonstrate how quantitative analysis can complement literary understanding. By combining statistical analysis and visualization, Verse Vectors aims to reveal hidden patterns in poetry while maintaining interpretative caution and analytical rigor.
How I built it
Technologies Used -Python -Pandas -NumPy -Matplotlib -Scikit-learn METHODOLOGY -Collected and loaded the Poetry Foundation dataset from Kaggle. -Cleaned and preprocessed the text data by: -Removing null entries -Normalizing text (lowercasing) -Basic text cleanup -Exploratory data analysis (EDA) to understand: -Distribution of poem lengths -Structural variations -Statistical summaries of text features -Engineered additional features such as: -Character count -Word count -Lexical analysis (unique words / total words) -Converted poem text into numerical vectors using TF-IDF (Term Frequency–Inverse Document Frequency) to represent linguistic importance. -Applied the KMeans clustering algorithm to group poems based on textual similarity. -Selected an appropriate number of clusters through experimentation and evaluation. -Reduced dimensionality using Principal Component Analysis (PCA) to project high-dimensional vectors into 2D space. -Visualized clusters to observe separation and patterns.
Challenges I ran into
Selecting an appropriate number of clusters for KMeans without predefined labels or ground truth.
Interpreting clusters meaningfully, since unsupervised learning does not provide explicit thematic labels.
Managing skewed distributions in poem length, where a small number of very long poems influenced statistical summaries.
Balancing computational efficiency and interpretability while limiting the number of TF-IDF features.
Translating abstract literary content into measurable numerical features without oversimplifying poetic nuance.
Accomplishments that I am proud of
Building a complete unsupervised learning pipeline from data preprocessing to clustering and visualization.
Extracting meaningful thematic patterns from poems without predefined labels.
Interpreting high-dimensional clusters in a way that connects machine learning output with literary understanding.
Visualizing clustered poems in reduced 2D space using PCA to make abstract vector relationships interpretable.
Designing a reproducible and well-structured notebook that clearly documents each stage of the analysis.
What I learned
The importance of preprocessing in NLP workflows.
How unsupervised learning can reveal patterns without labeled data.
The difficulty of choosing and interpreting clusters meaningfully.
How dimensionality reduction helps make complex data visually understandable.
What's next for Verse Vectors
Topic modeling using LDA
Word embeddings (Word2Vec, GloVe, BERT)
Sentiment analysis integration
Interactive visualization dashboards
Built With
- github
- kaggle
- matplotlib
- numpy
- pandas
- python
- scikit-learn
Log in or sign up for Devpost to join the conversation.