-
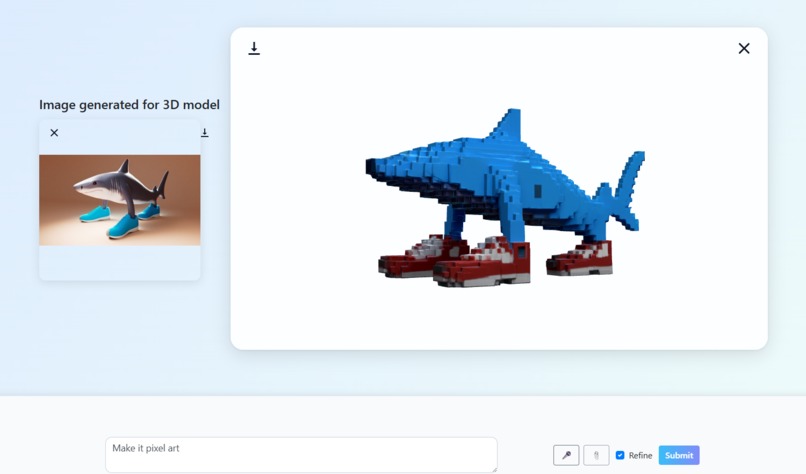
Dynamic 3D model generation from text/audio/image prompts
-
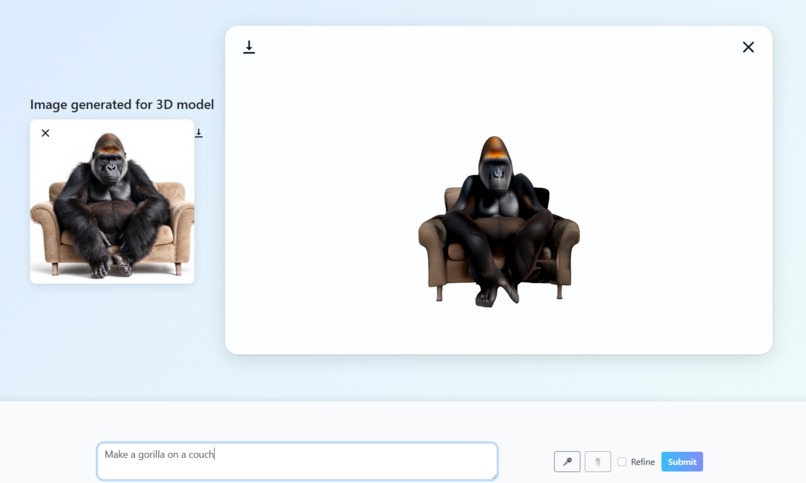
Generate a 3D model from a text/voice prompt
-
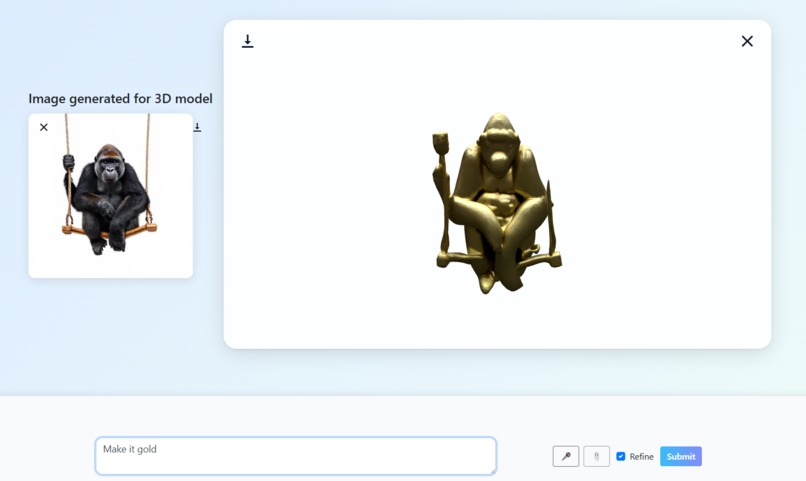
Iteratively refine the model through text/voice prompts
-
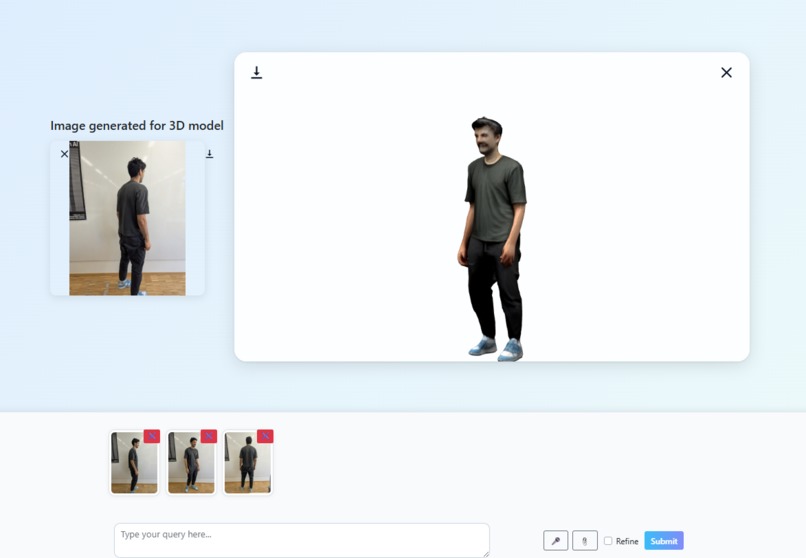
Generate 3D model from input images




Inspiration
We were inspired by the growing capabilities of multimodal AI and the bottlenecks that exist in 3D content creation. Traditional 3D modeling tools are powerful but have steep learning curves, making them inaccessible to many creatives, especially those without technical backgrounds. We wanted to build a tool that bridges this gap—something that allows anyone to transform and refine an idea into a 3D model, using just their voice, text, or images.
What it does
Our app enables users to generate and refine 3D models dynamically using natural inputs like text prompts, spoken descriptions, or reference images. The tool leverages cutting-edge multimodal AI models to interpret these inputs and generate 3D meshes, which can be quickly previewed and refined with further prompting. It transforms the 3D modeling process into a fast, intuitive, and collaborative experience.
How we built it
- Three.js for 3d visualisation in the browser
- Trellis for 3d model generation
- Together.ai API for image generation and image editing
- Flask for API
Challenges we ran into
- Deploying 3D generation model
- Limitations with generating 3D models from text prompts
- Limitations with directly refining 3D models
Accomplishments that we're proud of
We're proud of building a working prototype that transforms a simple idea into a tangible 3D model—without requiring any specialized skills. The multimodal interface is intuitive and inclusive, making advanced 3D creation accessible to designers, developers, and hobbyists alike.
What we learned
We gained deep insight into the capabilities and limitations of current generative 3D AI models. We also learned the importance of user experience when abstracting complex workflows.
What's next for Tralala
We plan to expand Tralala’s capabilities to directly support or feed into downstream applications, for example animation and rigging, 3D printing of the models, creating Unity assets etc.
Built With
- three.js
- together.ai
- trellis


Log in or sign up for Devpost to join the conversation.