-
-
How trace work ?
-
loading page
-
the user asks for a missing object
-

simulate data stream(send video to gemini)




Trace
Inspiration
For millions of people living with early-stage dementia, Alzheimer’s disease, or age-related memory decline, daily life can feel increasingly fragmented. Simple questions like “Did I turn off the stove?” or “Where did I put my medication?” create constant anxiety and slowly erode independence and dignity.
We realized that although cameras are everywhere—on our phones and increasingly in smart glasses—they are mostly passive. They record, but they do not understand. Trace was inspired by a simple idea: build a bridge between biological memory and digital perception. We wanted to create a “second brain” that doesn’t just archive life, but actively helps people navigate it.
Disclaimer: Trace is not a medical device and does not provide medical diagnosis, treatment, or clinical decision-making. It is an assistive, non-medical memory support tool designed to improve daily recall and autonomy. It is not intended to replace professional medical care.
What it does
Trace is a multimodal memory assistant designed for the future of wearable technology.
- Passive capture: Short video clips simulate a wearable point-of-view of daily actions.
- Semantic indexing: Videos are analyzed and stored as meaning, not raw pixels.
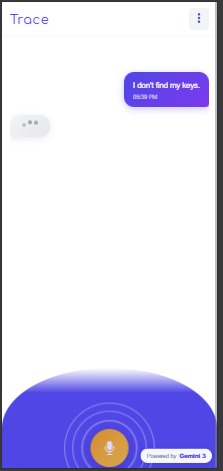
- Natural retrieval: Users ask questions like “Where are my keys?”
- Voice guidance: Trace responds with a calm, human-like voice, removing screen dependency.
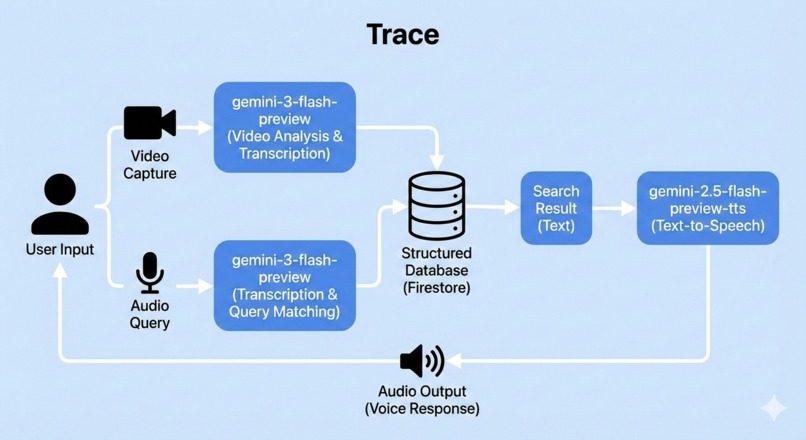
How we built it
Trace uses a decoupled architecture:
- Frontend: Ionic + Vue.js for an accessible mobile UI.
- Backend: Node.js (Express) orchestrating AI and data flow.
- AI core (Gemini):
- Video, transcription, and reasoning:
gemini-3-flash-preview - Voice output:
gemini-2.5-flash-preview-tts
- Video, transcription, and reasoning:
We define a retrieval function ( R(q, V) ), where ( q ) is the user query and ( V ) the set of video memories.
Scene understanding: $$ S_{scene} = {\text{objects}, \text{actions}, \text{location}, \text{timestamp}} $$
Challenges we ran into
- Rate limits & quotas: We encountered 429 errors and learned to optimize model choice.
- Context precision: Distinguishing between “holding” and “placing” objects required careful prompt engineering.
- Latency: Chaining transcription, search, and TTS demanded stream-level optimizations.
Accomplishments that we're proud of
- True multimodality: vision, audio, reasoning, and speech.
- Zero-UI interaction, crucial for elderly and cognitively vulnerable users.
- A scalable, production-ready architecture built during a hackathon.
What we learned
- Bigger models aren’t always better—Flash models excel at real-time understanding.
- In assistive technology, empathy and tone are as important as accuracy.
What's next for Trace
- Smart glasses integration for hands-free, always-on memory capture.
- Proactive alerts based on risk estimation: $$ \text{if } P(E_{danger}) > \theta \rightarrow \text{Trigger Alert} $$
- Privacy-first evolution, with more on-device processing and local memory stores.
Trace is not about replacing human memory—it’s about supporting it when it matters most.
Built With
- css
- express.js
- firebase
- firestore
- gemini
- github
- html
- ionic
- javascript
- node.js
- render
- vue.js

Log in or sign up for Devpost to join the conversation.