-
-

TomoTalk Logo
-
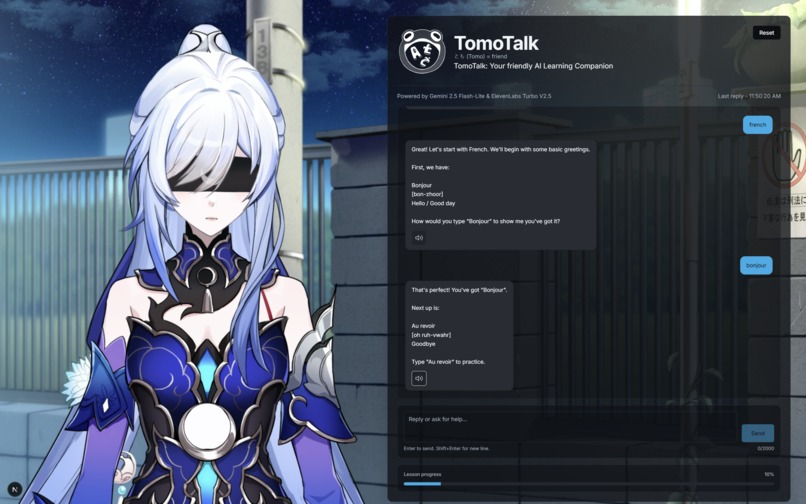
Image of our chat interface Character Example 1
-
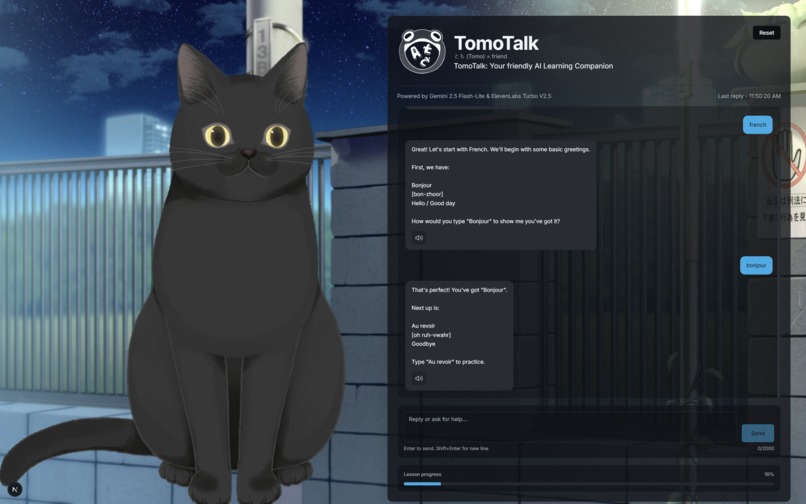
Image of our chat interface Character Example 2



Inspiration
Through watching Instagram reels of AI celebrities educating people about relevant topics we frequently encounter, we realized how engaging and immersive content makes a big difference in education. For example, reels of AI Kanye West teaching calculus. We found that users always have a personal connection and a sudden drive in motivation, wanting to learn, because it's taught by a character or person they are familiar with.
What it does
TomoTalk is an AI language learning tutor with built-in lessons for users featuring a matching character with audio as the output. On the left, we integrated an animated character that can follow the location of the user's mouse pointer with its eyes. This animated character also has a custom voice that we created to match the text. This animated character is significant in our project because it provides a similar drive in motivation to users like AI celebrities in reels. When the user first launches Tomotalk, they will be asked what language they want to learn. After the user inputs the language they want to learn, a series of texts and audio is displayed in the chatbox for a lesson to educate users. There is also a progress bar at the bottom for users to keep track of how well they are doing in each lesson.
How we built it
TomoTalk is an interactive web app built on Next.js. The frontend is styled using Shadcn UI components and TailwindCSS to provide a minimal and user-friendly user interface. Chat box responses are generated using the Gemini API with our custom language learning focused prompt, which is fed into the ElevenLabs API to generate audio output. We chose Gemini 2.5 flash-lite and ElevenLabs Turbo V2.5 to increase response speed to simulate a more dialogue-like experience. The animation is constructed by using Vtube Studio to animate a Live2D model to respond to the audio output of the ElevenLabs API.
Challenges we ran into
Some challenges we ran into were finding a good system prompt that would not return a long robot-like response. To overcome this issue, we researched prompt engineering as a team, rewrote our prompts, and also had our prompts refined by various LLM models.
Accomplishments that we're proud of
The accomplishment we're most proud of is learning new technologies, such as text-to-speech audio output and connecting our avatar with matching mouth movements. Getting the separate technologies we used to connect posed as an initial challenge; however, seeing everything come together felt very rewarding.
What we learned
We learned a combination of new technical skills, such as prompt engineering, for the most desirable and fitting possible output, along with how to best collaborate as a team. Specifically, we found it very valuable getting to brainstorm, ideate, and develop a product with individuals of different skill sets and to figure out how to best divide tasks. Breaking tasks down to small, actionable steps proved to be very useful and allowed us to collaborate efficiently. We also learned the importance of strong communication, which is important in keeping the team on track and on the same page.
What's next for TomoTalk
In our future roadmap, we plan to further refine our system prompts to improve response time and user experience, along with the ability for users to choose between different AI models for the response if they prefer a higher quality response over speed. We also plan to implement various other modes, such as a STEM tutor or a free chatting mode. We also plan to implement more UI elements, such as a home page and an authentication screen.


Log in or sign up for Devpost to join the conversation.