-

Our Logo
-
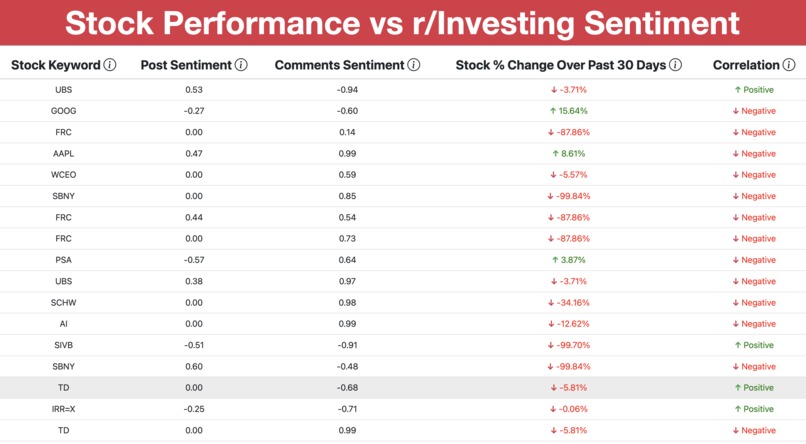
UI for showcasing our data findings
-
Screenshot of the data we scraped from Reddit r/Investing
-
Using Pandas to visualize csv files
-






Inspiration
For this hackathon, we wanted to focus on learning and using new tools to solve a problem related to us. We took note of the fact that recently a YouTuber did an experiment to compare how r/WallStreetBets compared to a goldfish when it came to investing and wanted to see how these subreddits and their sentiment towards stocks actually compared to the real thing. We thought it was an interesting way to learn new skills while investigating a topic.
What it does
Should you trust social media for your investment advice? Specifically, Reddit? This project scrapes investment-related subreddits and uses Natural Language Processing to provide sentiment analysis on popular stocks. The sentiment ratings are compared to the real performance of stocks to help you analyze if your Reddit advice is accurate!
How we built it
We started by harvesting our data by web scraping Reddit using an API library called PRAW in addition to Python Regex. From there we worked to filter this raw data into usable data that contained keywords and stocks interesting to us. This involved using the Python library Pandas to visualize the data we collected as CSV files. Once we found the relevant posts we then ran Natural Language Processing on our data to quantity user sentiment towards a particular stock. Following this, we serialized our data into JSON format for ease of access and flexibility. We also used Flask to help visualize all this data. In the backend, we connected our MongoDB database and handled data generation. In the frontend we created a table view that displays the information we collected about each stock in each column. We combined the post and comment sentiment into an overall sentiment for the stock. Finally, we compared it to the actual stock performance in the last column and visualized the results.
Challenges we ran into
- Quality of Data - while scraping on Reddit we found that we had to filter through junk posts and comments to prevent them from skewing our data sets.
- Data types - early in our project we realized we needed to decide on the best format to store data.
- Scope - we had big ideas and ambitions but we needed to evaluate our capabilities within the allotted time.
Accomplishments that we're proud of
We were proud of our ability to push our limits by choosing a topic and technologies we were not familiar with. We were also adaptive during this hackathon, choosing to switch between technologies when found necessary. Despite many difficulties, the team maintained a strong vision and mental fortitude throughout the long nights.
What we learned
We came in with limited knowledge about web development and web scraping, but throughout the hackathon, we were able to gain experience and ultimately accomplish the goals we initially set for ourselves by collecting and filtering data alongside a front-end visual representation. We learned a lot about the quality of data and the time constraints associated with processing data sets.
What's next for StockByte
In the future, we want to make the data a lot more comprehensive and provide a better user interface to allow for customization. We would like to allow the user to choose which subreddit to gather data on, and potentially expand to be a general sentiment tracker for subreddits and topics.




Log in or sign up for Devpost to join the conversation.