-
-
Room Sense

Inspiration
As a software engineer and a newer stand-up comedian in NYC, I live the painful feedback loop of comedy: write a joke, wait days for an open mic, tell the joke, bomb in silence, and repeat. The cycle to refine a solid 5 minutes can take months.
I realized that what comedians lack isn't a spellchecker; they need a Green Room. They need a safe, high-pressure environment to test material against veteran perspectives before hitting the stage. I built Room Sense to compress those months of iteration into a single sitting by simulating a room full of sharp, tired, honest comics.
What it does
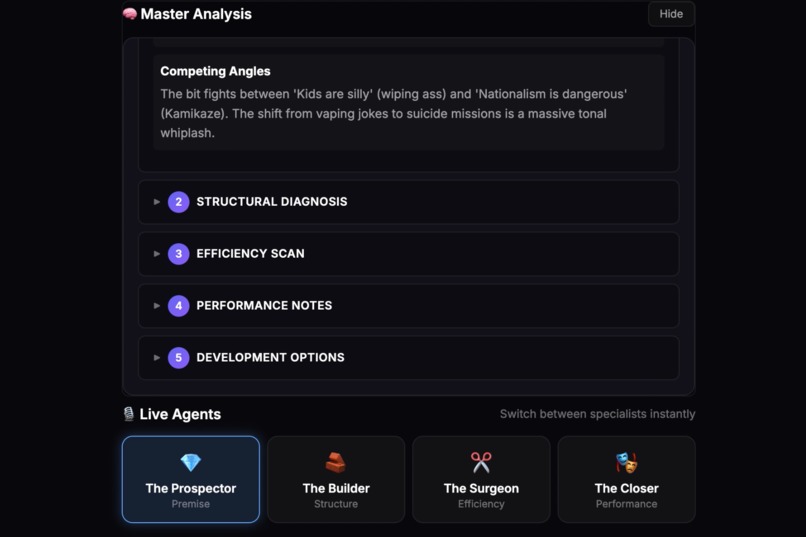
Room Sense is an AI-native performance laboratory. It allows comedians to upload their set and "jam" on it with AI.
- Master Analysis (The Blueprint): First, the system ingests the script and uses Gemini 3 Flash to generate a "Global Logic Map." It audits the premise, diagnoses structural health (using Rick Crom’s methods), and scans for efficiency (using John Roy’s methods).
- Live Coaching (The Green Room): The user then enters a real-time voice session. They can switch instantly between 4 specialized agents powered by Gemini 2.5 Flash Native Audio:
- 💎 The Prospector: Digs for the real, hidden premise.
- 🧱 The Builder: Fixes the setup-punchline structure.
- ✂️ The Surgeon: Ruthlessly cuts word count and "comma-talk."
- 🎭 The Closer: Coaches performance, rhythm, and conviction.
How we built it
We utilized a Dual-Model Architecture to combine deep reasoning with low-latency interaction.
- The Brain (Gemini 3 Flash): We used the high-reasoning capabilities of Gemini 3 to act as the "Director." It analyzes the text deeply to create a structured JSON blueprint of the set's logic, identifying hidden premises and conflicting angles.
- The Voice (Gemini 2.5 Flash): For the live agents, we used the Native Audio capabilities via WebSockets. This was critical because comedy relies on timing. Traditional STT->LLM->TTS pipelines are too slow and kill the joke.
- Audio Pipeline: We implemented a custom
AudioWorkletin the browser to capture raw PCM audio (16kHz), which streams directly to the Gemini Live API. - Context Injection: When a user switches agents (e.g., from The Builder to The Surgeon), the app injects the recent transcript history and the relevant section of the Master Blueprint into the new agent's system prompt, preserving the "jam session" flow.
Challenges we ran into
- The "Helper" Problem: Default AI models are too polite. A good comedy coach needs to be short, sharp, and slightly cynical. We had to heavily prompt-engineer a "Response Contract" to force the agents to use comic shorthand (e.g., "Kill the list, it's boring") rather than lecturing the user.
- State Management: Coordinating the state between the static analysis (Gemini 3) and the fluid live conversation (Gemini 2.5) was tricky. We solved this by treating the Gemini 3 output as a "dynamic context object" that the live agents reference.
- Audio Feedback: Managing echo cancellation in a browser-based real-time voice app required careful tuning of the
AudioContext.
Accomplishments that we're proud of
- Native Audio Latency: The speed of response allows for actual "beter-and" improv. You can interrupt the AI, and it feels natural.
- Agent Personality: Distinctly capturing different coaching styles (The Surgeon vs. The Prospector) creates a genuine feeling of having a diverse team working on your set.
- The Analysis Quality: Gemini 3's ability to distinguish between a stated premise and a hidden premise was surprisingly human-like and offered genuine artistic insight.
What we learned
- Multimodal is King: For performance art, text-based feedback is insufficient. The Native Audio model picks up on hesitation ("upspeak") and lack of conviction in a way text models never could.
- Reasoning + Speed: Combining a heavy reasoning model (for the map) with a fast model (for the journey) is a powerful pattern for complex coaching applications.
What's next for Room Sense
- Heckler Mode: An agent designed specifically to disrupt the user to practice crowd work.
- Video Analysis: Using Gemini's vision capabilities to analyze physical stage presence and mannerisms.
- Mobile App: A "Car Ride" mode for comedians to practice their set hands-free on the way to the club.
Built With
- audioworklet
- firebase-hosting
- gemini-2.5-flash-audio
- gemini-3-flash
- google-cloud-run
- javascript
- webaudio-api
- websockets

Log in or sign up for Devpost to join the conversation.