-
-
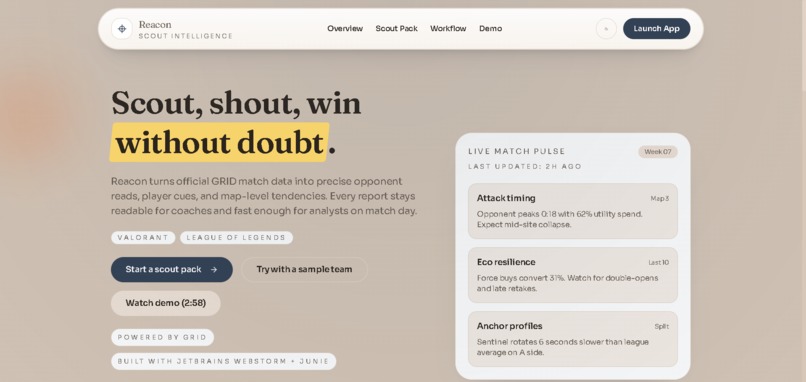
Landing Page
-
AI-Chat Interface
-
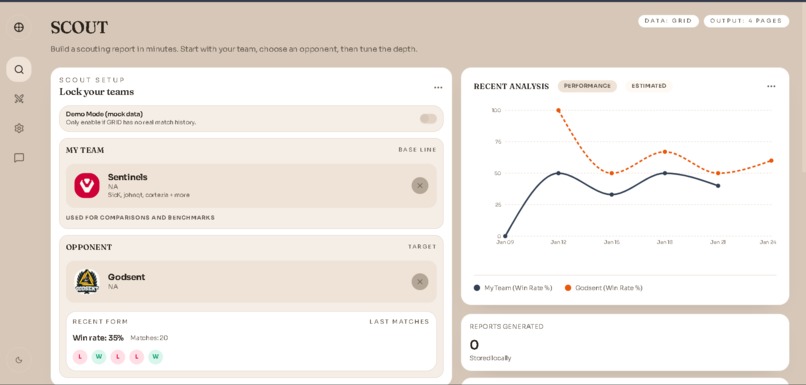
Scout Page



Inspiration
Before every match, coaches and analysts have to answer the same questions fast: What does the opponent default to? Who are the key players? What do they do when pressured? In practice, scouting often becomes hours of VOD review, scattered notes, and spreadsheets under time pressure and with inconsistent conclusions.
I wanted to build a tool that turns official match history into a coach-ready scouting report in minutes, while still being trustworthy enough to use in prep.
What Reacon does
Reacon (ScoutVision) is an automated scouting report generator for VALORANT and League of Legends. You enter an opponent team and choose a recent match window (e.g., last 10 matches), and Reacon generates a concise scouting pack that includes:
- Common team-wide strategies and macro patterns
- Key player tendencies and champion/agent pools
- Recent compositions/setups (where data supports it)
- Ranked “How to Win” recommendations (counter-strategies and exploitable weaknesses)
The most important part: Reacon shows the reasoning/evidence behind insights so it’s not just “AI vibes.”
How we built it
Stack
- Next.js 15 (App Router) + TypeScript
- Bun runtime
- Tailwind CSS + Radix UI + Framer Motion
- Recharts for interactive visuals
- Official esports data from the GRID API
- Google Gemini for analysis and report generation
- Optional persistence for report history (stored as derived summaries, not raw GRID payloads)
Pipeline
- Team search + selection
- Fetch recent match/series history from GRID
- Build an evidence index from the match window (series IDs + metadata)
- Send structured inputs to Gemini to generate a multi-section report
- Render the report as a coach-friendly pack with tabs (Summary / Team / Strategy / Actions / Changes)
Evidence Mode (trust by design)
A major requirement for Category 2 is that the system should provide the data or reasoning behind insights. Reacon addresses this with Evidence Mode:
- Each key insight can show the supporting series IDs from the match window
- Evidence IDs are enforced end-to-end: the model is constrained to allowed IDs, and the UI filters out anything that doesn’t match the real evidence index
- The report header clearly labels the data source (Live GRID vs Demo Mode), so provenance is never ambiguous
Challenges we ran into
- Data integrity vs. user experience: We added strict provenance rules so the app will not silently use simulated data while claiming GRID-backed output. Demo Mode is explicit and clearly labeled.
- Preventing hallucinated numbers: LLMs love to invent precise percentages. We tightened prompts and UI rules so numeric claims only appear when computed from provided inputs; otherwise we use qualitative language with confidence levels.
- Consistency in structured output: Getting a long, multi-section scouting report to stay parseable and scannable required careful formatting constraints and iterative prompt design.
- Demo resilience: External APIs can rate limit or fail. We added retries, friendly errors, and clear fallbacks so the demo remains stable.
What we learned
- Coaches don’t need more dashboards—they need decisions: what to ban/deny, what to target, what plan to run, and why.
- Trust features (evidence, provenance labeling, honest confidence) matter as much as the analysis itself.
- Tight constraints and validation are essential when using an LLM in a “data-backed” product.
Algorithms & Equations
- Rolling win rate smoothing: Each window ( \mathcal{W}_i ) (up to 10 matches) computes win rate as $$[ \text{WR}(\mathcal{W}_i) = \frac{|{m \in \mathcal{W}_i : \text{result}(m) = \text{win}}|}{|\mathcal{W}_i|} \cdot 100]$$
Then points are merged by a normalized date key to reduce noise and keep charts readable.
Deterministic diff: Extracted report facts are normalized, hashed, and compared field-by-field before Gemini is asked for a human-readable “what changed” summary. This guarantees stable diffs independent of ordering and prevents the LLM from inventing changes.
Exponential backoff: For transient GRID/Gemini failures (e.g., 429/5xx), retries use exponential backoff: $$[ \text{delay}_n = 500 \cdot 2^n \ \text{ms}, \quad n \le 3]$$ This respects rate limits while still recovering during brief spikes.
What’s next
- Deeper comp/setup detection where GRID coverage supports it
- More deterministic derived stats from the match window (less inference)
- Practice-plan output (drills tied to specific weaknesses)
- Alerts when tracked opponents play new matches, so scouting stays fresh
Built with JetBrains WebStorm + Junie, powered by GRID and Google Gemini.
Built With
- css
- gemini
- grid
- javascript
- jetbrains
- junie
- lucidchart
- react
- supabase
- typescript
- webstorm



Log in or sign up for Devpost to join the conversation.