-
 GIF
GIF
Block that needs 2 robots, 3rd observes this so no work, when they reach the end and cant move (constraint of sim) pheromone emit for help
-
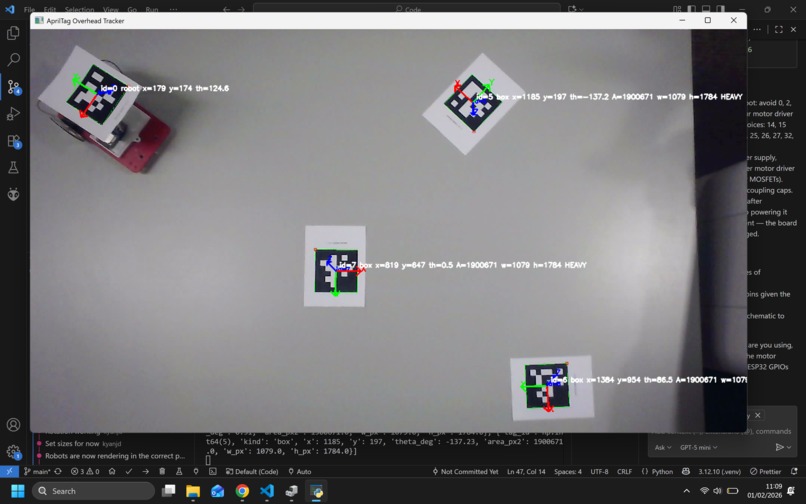
Screenshot of computer vision of robot and box location that robot FOV is derived from
-
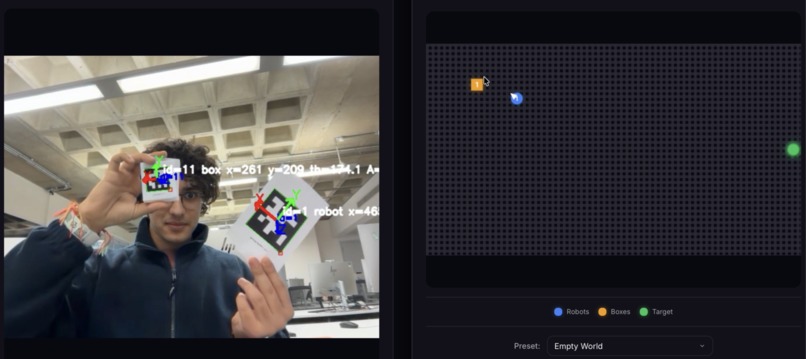
Real time digital twin of problem showing robot direction and box position



Swarm Robotics Project: Emergent Coordination
Inspiration
Our project was inspired by distributed cybersecurity systems, where independent agents monitor locally and, upon detecting a threat, emit a signal to recruit additional resources. We wanted to replicate this behaviour in a physical setting using swarm robotics, testing whether emergent coordination could arise without a central brain, purely from local inference about when and where help was needed.
System Design
Each robot was equipped with a local reinforcement learning policy and a virtual pheromone mechanism. When a robot struggled to complete its task, such as pushing an object, it emitted a pheromone signal with a spatial gradient proportional to the difficulty encountered. Other robots responded only to local pheromone cues, yet collective behaviours emerged. Robots dynamically formed groups around high-resistance tasks, coordinated force application, and dispersed once the task was complete, without any explicit task allocation or global oversight.
Through this process, we observed how emergent behaviour can arise from distributed learning, indirect communication, and environmental feedback. Simple local rules, rewarding progress, responding to pheromone gradients, and avoiding counterproductive interference, were sufficient to produce efficient, adaptive collective strategies that replaced explicit coordination and centralised planning.
Deployment Challenges
The main challenge was deployment. Ideally, each robot would run its own onboard learning model, but hardware and cloud constraints made this infeasible within the project timeline. Instead, all ESPs were linked to a central controller that executed motion commands, while decision-making remained decentralised through independently trained reinforcement learning policies. This hybrid architecture preserved emergent behaviour while remaining practical to implement.
Reinforcement Learning Challenges
A further challenge lay in designing the reinforcement learning framework itself, particularly the reward structure. Naive rewards led to individualistic or unstable behaviours, whereas carefully shaped rewards encouraged cooperation to emerge only when required. The robots had to learn not just how to move blocks, but when teamwork was necessary and how to synchronise their actions. Balancing individual incentives with shared task progress was critical to achieving stable, repeatable emergent cooperation rather than brittle or hard-coded solutions.

Log in or sign up for Devpost to join the conversation.