-
-

PaperTrail
-
PaperTrail App


Inspiration
My Inspiration began with news and ended with research papers. This project was NewsTrail first and then it became PaperTrail. To begin with ...
I’m tired of the challenges in keeping up with the news. Often, multiple articles need to be referenced to fully understand a story, but tracking them all is difficult. While some articles provide background information, it’s usually summarized, incomplete, or even misleading. NewsTrail addresses these issues directly. Imagine being able to trace related articles back to their original sources. This would give users a complete understanding of the story while discouraging journalists from spreading or amplifying misinformation. NewsTrail had two main features, search for latest news and visualize its timelines, and a chatbot that can directly provide information according to the user questions. However, I faced major setbacks with data (discussed more in "Challenges the project ran into").
This led to the development of a new project called PaperTrail. Just like news articles, research papers also need to be tracked for better understanding. I created a simple platform for searching research papers that not only provides similar papers but also presents them on a timeline.
What does PaperTrail do?
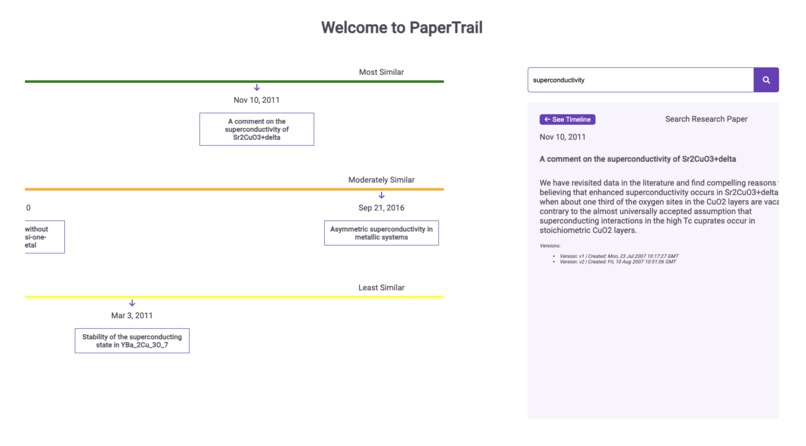
PaperTrail allows users to search for research papers on any topic they choose. It finds the most relevant and recent papers for the user. If a direct link to the paper is available, the user can open it in a new tab. If not, the user can perform a quick search in a new tab. For users interested in exploring similar papers, PaperTrail offers a timeline view. There are three timeline options to choose from: most similar papers, moderately similar papers, and least similar papers.
How was the project built?
The PaperTrail project was built with a robust architecture that leverages Python, Node.js, and Angular to manage and display research papers efficiently. Python was used to extract research paper data from CSV files and load it into a TiDB database. The data, along with embeddings generated via the JINA API, were stored to facilitate advanced search functionalities. The frontend, developed in Angular, handles user interactions and displays research paper data dynamically.
On the backend, implemented using Node.js and Express.js, search functionality is achieved through a systematic approach. Two methods are implemented for handling search queries. In the first approach, the backend generates embeddings for the query and then iterates through different similarity thresholds to find papers with cosine similarity above a certain threshold. It aggregates and sorts these papers based on similarity scores, ultimately selecting the top results based on similarity and recency. The second approach, on the other hand, focuses on identifying the single most relevant paper by tracking the highest similarity score across different thresholds, returning the best match. Both methods involve parsing embeddings from the database, calculating similarity scores, and handling errors in data parsing to ensure accurate search results.
Challenges the project ran into.
The biggest challenge in handling data was sourcing appropriate information. Initially, with the NewsTrail project, I struggled with a ~5GB dataset imported via S3 due to its unclean nature, making data cleaning very difficult. I eventually switched to using the News API, which provided fresh data with each search and facilitated scaling the database daily. However, the API lacked complete article details, leading to inaccurate search results.
For the revised project involving research papers, PaperTrail, I faced similar issues with obtaining full article information. Consequently, the search was limited to titles and abstracts. With only abstract data available, creating a chatbot proved impractical as it would only offer incomplete information. It became clear that it was better not to provide any information rather than risk delivering inaccurate details.
Accomplishments to be proud of.
- Integration of Python and JINA API to store data with embeddings in TiDB.
- Implemented a search system using cosine similarity and embedding-based ranking for accurate and nuanced paper retrieval.
What was learnt from this project?
- Gained expertise in TiDB's vector search and managing large datasets.
- Improved in resolving data parsing and embedding calculation issues.
What's next for PaperTrail
- Data: Prioritize obtaining high-quality data and improve the data cleaning process.
- Chatbot: Develop a chatbot using clean data and robust NLP processing to ensure accurate and helpful interactions.
- User Creation: Implement user account creation to allow users to develop personalized research roadmaps and assist them in writing their own research papers.

Log in or sign up for Devpost to join the conversation.