-
-
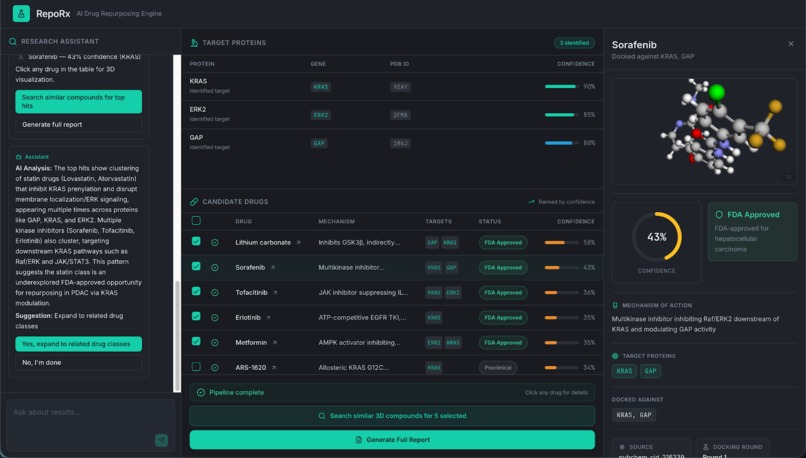
Final results in our dashboard
-

Why Repurpose Drugs
-

Solving Invisible Part Of the Research Pipeline
-

Metformin Case Study
-
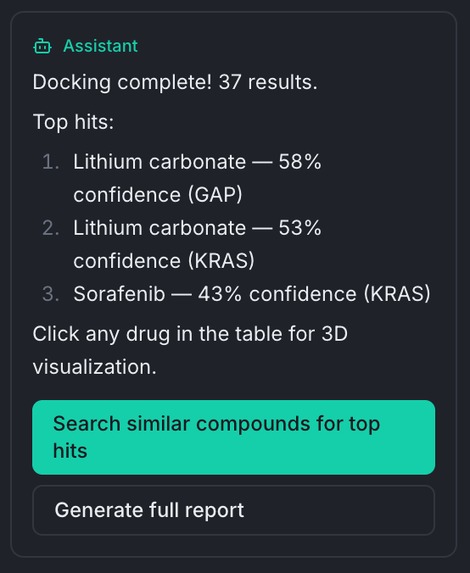
Some very promising compounds
-

An analysis of the study






The Cure That Was Already There
A potential cancer treatment sat in medicine cabinets for 50 years before anyone noticed. Metformin, one of the most common diabetes drugs in the world, wasn't investigated for pancreatic cancer until 2005 — half a century after FDA approval. We’re making sure that never happens again.
We’re focusing on repurposing already FDA-approved drugs. Developing a new cancer drug through the FDA approval process typically takes 10–15 years and over $1 billion, creating a major bottleneck for patients who urgently need better treatments. Repurposing already FDA-approved drugs offers an easier path.
Recently, there are new tools to simulate drugs and their effectiveness in targeting cancer, but the research space is simply too large to try all of them.
So we built, RepoRx, a research platform for discovering potential cancer treatments in drugs that were never designed for cancer.
See more about the why here.
What it does
Our agents
- Compose a full literature review that synthesizes current research
- Identify proteins to target, and relevant drugs
- Run experiments to simulate the interaction between the proteins and compounds
Output:
- Full research report to share
- Simulation results that show the most promising drugs to take to wet labs
- Confidence scores assigned to each drug candidate
Once the outputs are received, researchers can take them to the wet lab or continue searching for compounds with similar molecular structures in order to find more potential drugs – right on our platform.
How we built it
- We built a modular, multi-agent pipeline in TypeScript with a Next.js + Tailwind frontend. The app is hosted on Vercel. Each agent handles a distinct phase of the workflow and communicates via structured JSON, allowing independent development, debugging, and resumable execution.
- Orchestrated agent flows using Fetch.ai – registered an agent on AgentVerse where it can be used in ASI:One, an alternative UI to our platform.
- Using the arXiv API and Perplexity AI (Sonar Pro Deep Research), the system synthesizes current research for a selected cancer type and extracts high-impact protein targets (e.g., EGFR, KRAS, p53), along with known drugs, mechanisms of action, and FDA status.
- The agent retrieves high-resolution protein structures from the RCSB Protein Data Bank and queries PubChem to collect and expand candidate compounds. RDKit canonicalizes SMILES - strings for docking compatibility.
- We run DiffDock on RunPod serverless GPUs (Nvidia Blackwells) to predict protein–ligand binding. Ligands are processed in parallel batches, generating multiple poses per pair and ranking candidates by confidence score (0–1).
- Docking results are classified into cancer-approved drugs, repurposing candidates, and novel compounds. The system generates a ranked repurposing leaderboard and automatically produces structured research summaries using Perplexity AI. A final assistant agent explains the results and future recommendations interactively.
Challenges we ran into
- Running DiffDock locally wasn’t feasible due to GPU and memory limitations. We had to provision cloud infrastructure on RunPod and deploy to virtual NVIDIA Blackwell GPUs to handle large-scale docking simulations. This required setting up remote job orchestration, batching, and polling logic under tight time constraints.
- DiffDock requires clean, consistent structural inputs. Converting compounds from PubChem into canonicalized SMILES and compatible 3D formats introduced edge cases (naming conflicts, malformed structures, conversion mismatches). Ensuring filesystem-safe ligand naming while preserving metadata required additional preprocessing and validation layers.
- We initially built the backend in Python (Flask), but migrated to a full TypeScript stack mid-hackathon for better compatibility with Vercel deployment and frontend integration. This required refactoring API orchestration, async workflows, and agent communication under time pressure.
- Because our system surfaces drug recommendations in a clinical domain, we had to think carefully about disclaimers, scope limitation, and responsible framing. Determining where human oversight is required—and ensuring the system is positioned as a research aid rather than a clinical decision-maker—was an important design consideration.
Accomplishments that we're proud of
- We built a system that takes a single cancer-type input and autonomously performs literature synthesis, target identification, structure retrieval, compound discovery, molecular docking with DiffDock, classification, and report generation—compressing what typically a lab takes weeks or months to research into one automated workflow that completes in several minutes.
- We deployed real large-scale docking simulations on cloud GPUs via RunPod, using a physics-informed diffusion model, generating ranked confidence scores across multiple protein–drug pairs in parallel.
- Despite migrating tech stacks mid-hackathon and provisioning GPU infrastructure from scratch, we delivered a production-style TypeScript backend with a deployable Next.js frontend.
What we learned
- Building in the medical domain forced us to think beyond technical performance. Even though our system is research-focused, surfacing drug recommendations carries real-world implications. We learned the importance of positioning the platform as a decision-support tool and not an authority, clearly defining its scope.
- In healthcare, outputs can influence high-stakes decisions. We had to consider disclaimers, human-in-the-loop checkpoints, and how recommendations are communicated.
What's next
- We plan to incorporate patient-specific safety constraints, including pre-existing conditions, contraindications, and known adverse interaction profiles. This will allow the system to filter or down-rank compounds that may pose elevated clinical risk, improving real-world viability.
- We want to make the workflow fully iterative: allowing users to move forward or backward between stages (e.g., refining target selection after docking results, expanding compound libraries, or re-running simulations with adjusted constraints).
- For top-ranked candidates, we aim to integrate more rigorous physics-based methods beyond DiffDock, such as molecular dynamics simulations and free-energy calculations, to improve binding accuracy and reduce false positives.
- Once computational confidence is strengthened, the next step is structured recommendation for wet-lab validation prioritizing compounds with strong predicted binding, established safety profiles, and mechanistic plausibility for in vitro testing.
Built With
- arxiv
- diffdock
- docker
- fetch.ai
- next.js
- pdb
- perplexity
- pubchem
- rcsb-protein-data-bank
- rdkit
- runpod
- tailwind
- typescript
- vercel






Log in or sign up for Devpost to join the conversation.