-
-

Le CopyChat by Samarth and Johann Diep.
-
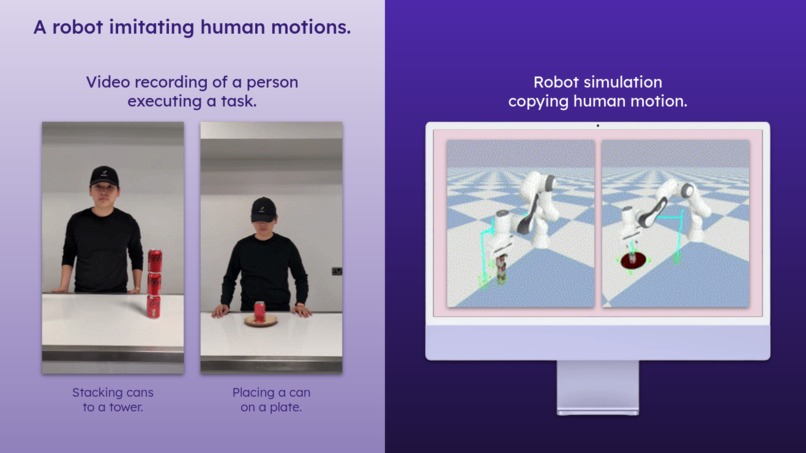
Imitating human tasks.
-
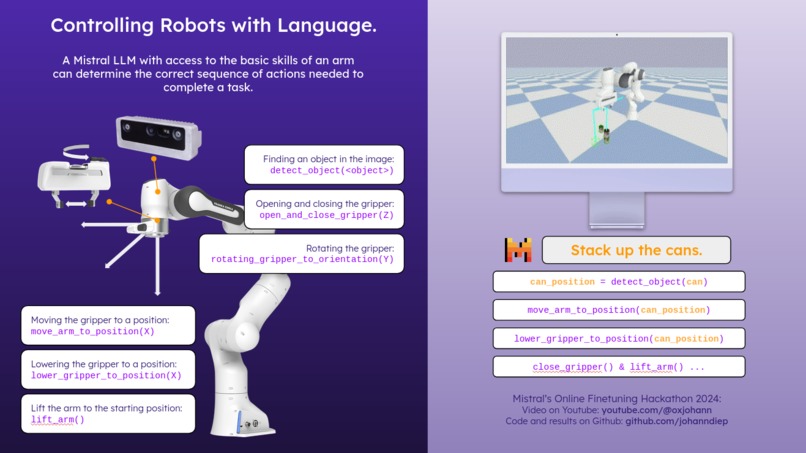
Control robots with natural language.
-

Keyframe extraction with visual embedding similarity method.
-
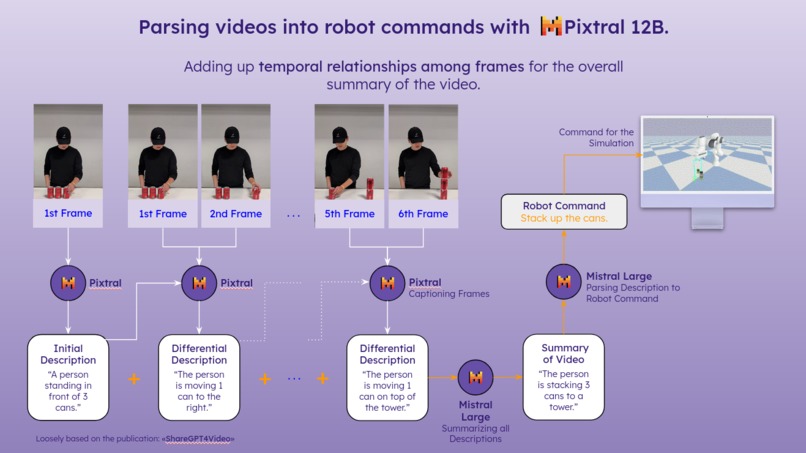
Adding up temporal relationships among frames for the overall summary of the video.





Inspiration
Today’s robots are like computers from the 80s - very complicated and only usable by experts with years of experience. Programming them to do even one simple task is tough and requires a lot of technical knowledge. For robots to become everyday helpers, whether for repetitive tasks or heavy object lifting, learning new skills needs to be much easier.
Most of us learn new skills by watching YouTube tutorials. The question is, can robots do the same - learn a skill just by watching a human in a video?
What it does
For robots to become everyday helpers, whether for repetitive tasks or heavy lifting, we need to make teaching them as simple as watching a tutorial video.
In a previous Mistral hackathon (youtube.com/watch?v=_vsRd8RsCKo), we showed that a fine-tuned Mistral LLM could generate code to control a robot just by understanding natural language robot commands, such as "build a can tower" or "put the can on a plate". For the current hackathon, we took it further by adding a video summarizer that watches a human demonstration, summarizes the actions in the video, and translates them into commands the robot can follow.
How we built it
First, we separate the human demonstration video into individual frames. To keep only the important frames where distinct human actions occur, we used a method based on visual embedding similarity to get the keyframes.
After extracting the keyframes, we used Pixtral and Mistral Large to create a summary of the video. We started by generating an initial description based on the first frame using Pixtral. Then, with the same model we created descriptions for each pair of consecutive frames and the previous description, capturing the changes over time. Finally, we summarized all these descriptions into a cohesive summary using the Mistral Large model. Another Mistral Large model then converted this summary into a robot command.
Challenges we ran into
A video has too many frames for Pixtral to process effectively, so we focus on keyframes by using a method based on visual similarity to extract them.
Additionally, Pixtral isn't designed to generate video summaries directly. Feeding all the keyframes into a single Pixtral call doesn't produce good summaries because it misses the temporal relationships between frames. By capturing the differences between consecutive frames with our method, we can maintain these temporal relationships, allowing us to create a cohesive summary of the video.
Accomplishments that we're proud of
We built a functioning pipeline in just over a day that enables robots to learn new skills from videos, much like humans do. It’s not just about copying human movements, the robot understands the task at hand and can perform it successfully, even if the starting conditions aren’t the same as in the video. For example, even if the cans for the robot to pick are arranged differently compared to the video, the robot can still complete the task.
What we learned
- Teamwork and planning achievable goals within time constraints.
- Tackling challenging problems while fatigued and embracing the process.
What's next for Le CopyChat
We want to test the method on more complex tasks, like assembling small electronic devices.


Log in or sign up for Devpost to join the conversation.