-
-

Landing page
-
Prompt
-
Generation
-
Cache hit
-
Dashboard





Inspiration
Every LLM interaction has a cost, measured in tokens, in dollars, and increasingly, in environmental impact. Data centers consume enormous amounts of energy and water to run the compute behind every AI response. We kept asking: how much of that is genuinely necessary?
The truth is, a huge portion of LLM queries are semantically similar to ones already answered before. The model is being asked to re-generate the same knowledge, in roughly the same shape, over and over again, wasting tokens, increasing costs, and burning compute that doesn't need to be burned.
InferOpt was born from the belief that smarter caching isn't just a performance optimization, it's an environmental responsibility. We wanted to build a system that learns how responses are structured and only calls the model for the parts that actually need fresh inference. Less waste. Lower cost. Longer conversations.
What It Does
InferOpt is a semantic caching and template engine that sits between your application and your LLM. Instead of firing a full prompt at the model on every request, InferOpt:
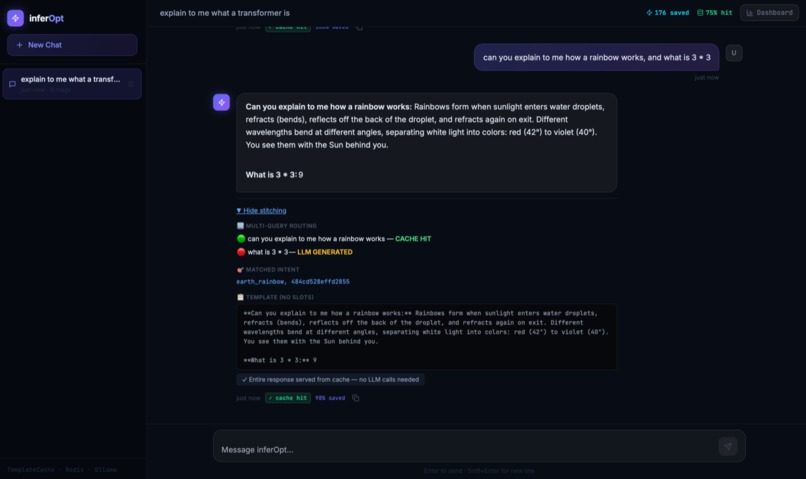
- Recognizes intent : matches incoming queries to known response patterns using semantic embeddings and k-means cluster routing across 604 cached intent centroids, not brittle string matching.
- Serves cached templates : pulls a pre-built response skeleton with placeholder slots (e.g.
[creator:quoted_content],[year_founded:number]) that capture the structure of a previous answer. - Fills only what's changed : slots with high confidence are served from cache at zero token cost. Blend zone slots use a confidence-weighted probabilistic draw between cached and fresh values. Only uncertain slots trigger a real LLM call : and even then, cross-query slot transfer tries to reuse a fill from a semantically related query before calling the model.
- Extracts precise answers from cached lists : when a specific factual question matches a cached list response, InferOpt extracts the single relevant item rather than returning the full list. Compound queries that ask for both a specific answer and the full list get both, formatted correctly.
- Learns and adapts: when users ask about aspects a template doesn't cover, InferOpt detects the gap, classifies it into one of 7 types, logs it, and automatically promotes recurring gaps into permanent template slots. Centroids update via rolling averages on every cache hit, so routing improves continuously without retraining.
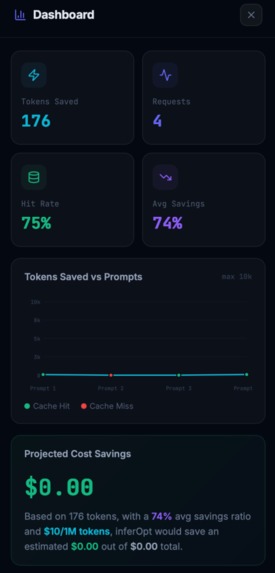
The result is a 55–75% reduction in output tokens on typical traffic, meaning lower API bills, higher rate limit headroom, and users who can simply chat for longer.
How We Built It
InferOpt is a multi-phase pipeline written in Python, backed by Redis and pluggable LLM backends (Ollama locally, OpenAI in production).
Phase 0 : Startup seeding
On first query, the system seeds 512 examples across 90+ intent types from a curated seed cache. Each example group is batch-embedded, averaged into a centroid, and stored in Redis alongside an extracted response template. Once 50+ centroids exist, k-means clustering groups them into 24 clusters for fast two-phase retrieval.
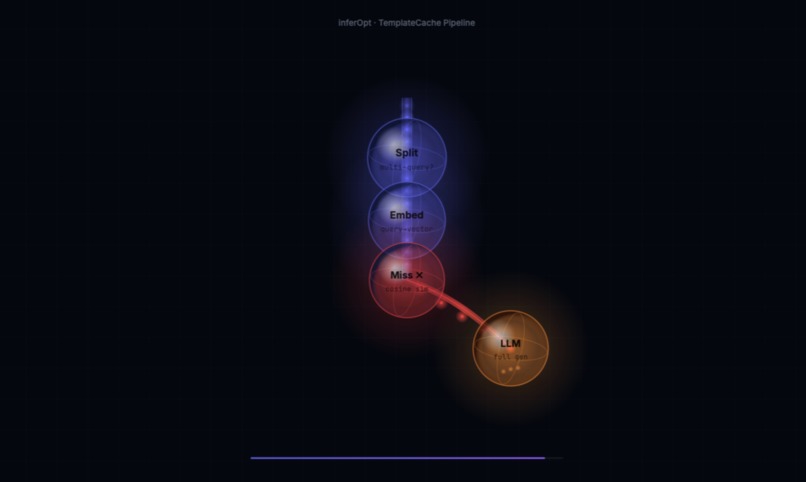
Phase 1 : Multi-query split
Compound queries are split on question marks, conjunctions, and semantic distinctness checks (cosine similarity < 0.45). Pronoun references in sub-questions are resolved by injecting the topic from the original query before routing. Each sub-question is processed independently and results are merged.
Phase 2 : Intent routing
A ClusterRouter embeds the query, scores it against 24 cluster centers, then against individual centroids within the top clusters. When the top match belongs to the wrong semantic domain, a cross-domain rescue scan fires unconditionally against all 604 centroids in the correct domain. Within-domain subdomain correction (planets vs stars within space, countries vs cities within geography) provides a second tier of disambiguation.
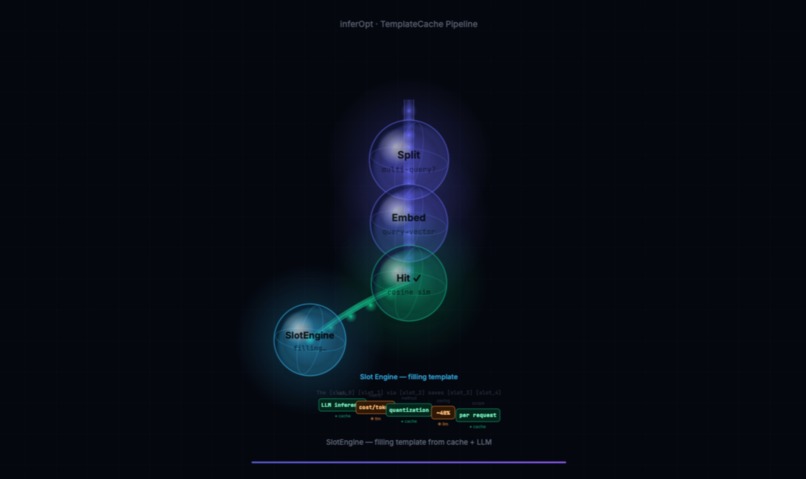
Phase 3 : Slot filling
The SlotEngine topologically sorts slots by dependency, then classifies each into three confidence states:
- Confident → serve from cache, zero tokens
- Blend zone → call LLM for a fresh value, then use the confidence score as a probability weight to select between cached and fresh, a 0.72 confidence score means the cached value is selected 72% of the time
- Uncertain → attempt cross-query slot transfer from semantically similar fills of the same slot type (with a 0.15 confidence penalty), fall back to a targeted single-slot LLM call if transfer fails
Per-slot-type confidence thresholds (currency at 0.85, date at 0.82, named entity at 0.80, boilerplate at 0.50) and time-decay on cached values keep freshness in check. Query context sanitization prevents domain contamination, if the query is semantically distant from the template, slot prompts are built without query context to stop cross-domain artifacts leaking into fills.
Phase 3.5 : Answer extraction
When a list-variant template matches a superlative query ("what is the largest planet"), a scoring pass extracts the single relevant item rather than returning the full list. Compound queries ("name the largest planet then list the rest") trigger a compound formatter that prepends the extracted answer to the full list response. Both paths return at zero token cost from cache.
Phase 4 : Gap learning
Detected gaps are classified into 7 types (temporal, comparison, quantitative, causal, procedural, example, elaboration), stored in Redis, and promoted to permanent template slots once 3 recurring gap events are recorded for the same template. Each promotion is logged and tracked, templates can only promote each gap type once, preventing duplicate slots.
Demo layer
A FastAPI server exposes POST /query and GET /stats, with a frontend dashboard tracking token savings, cache hit rates, slot transfer counts, blend zone selections, and evolved template counts in real time.
Challenges We Ran Into
Designing a novel pipeline architecture was the biggest challenge. There was no established blueprint for a system that combines semantic routing, template extraction, confidence-weighted slot filling, cross-query slot transfer, and self-adapting gap learning into a single coherent pipeline. Every component had to be designed with the others in mind, the dependency graph for slots, the fallback ratios, the decay model, the blend zone thresholds, and getting those interfaces right took significant iteration.
Routing precision across semantically adjacent intents was harder than expected. Standard cosine similarity scores for phrases like "largest planet" and "largest country" are close enough that naive threshold-based routing consistently misrouted queries. Solving this required building a three-tier routing correction system: domain keyword matching, subdomain keyword tie-breaking, and an unconditional cross-domain rescue scan, none of which were in the original design.
Stitching cached and fresh content seamlessly was technically the hardest sub-problem. Blending a cached slot value with a freshly inferred one, especially across different LLM response styles, required careful confidence weighting, query context sanitisation to prevent domain contamination, and a clean-fill pass to strip leaked slot name artifacts from LLM outputs. Getting stitched responses to read naturally with no visible seams required far more edge-case handling than anticipated.
Accomplishments That We're Proud Of
- 55–75% token reduction on real mixed traffic : a genuine, measurable impact on compute waste
- A self-adapting cache that improves without manual intervention: centroids update via rolling averages on every hit, gap learning continuously evolves templates from real user behaviour, and cross-query slot transfer propagates knowledge laterally across intent boundaries
- A novel pipeline architecture that cleanly separates routing, confidence classification, slot filling, answer extraction, and gap learning into composable, independently testable phases 86 passing tests with no LLM or Redis required to run them
- Code-aware caching : responses above 60% code content are flagged as non-templateable and served verbatim, preventing the slot engine from attempting to template content that changes structurally with every query
- Building an environmentally conscious solution for LLM inference one that frames cost efficiency and sustainability as the same problem
What We Learned
Building InferOpt was a deep dive into areas none of us had worked in at this depth before:
- Semantics and NLP : how meaning is encoded in embeddings, and how to use similarity search to route intent reliably at scale
- Tokenization : what tokens actually represent and why minimizing them is a structurally interesting problem, not just a billing one
- Embeddings and vector spaces : cosine similarity, embedding drift, domain contamination, and how to design thresholds that hold across different embedding models
- Clustering and nearest-neighbour search : k-means in practice, cluster boundary effects, subdomain disambiguation, and when full-domain rescue scans beat cluster routing
- Confidence calibration : the difference between a threshold and a calibrated probability, and why treating confidence as a continuous weight rather than a binary gate produces more useful system behaviour
- Software development lifecycle at system scale : designing interfaces between components that can evolve independently, writing for testability, and managing complexity across a multi-phase async pipeline
What's Next for InferOpt
InferOpt is a research prototype today : but the underlying idea scales. Next steps include:
- Per-intent threshold auto-tuning : the pipeline already logs enough data (wrong serve rates, gap rates, fallback ratios per intent) to tune routing and confidence thresholds automatically rather than setting them as global constants
- Multi-turn context awareness : extending slot filling to carry context across conversation turns, so a slot filled in one query can be reused in follow-up queries without re-inference
- Confidence calibration model : replacing the fixed per-type threshold table with a trained model that predicts the probability a cached slot value is still correct, using slot type, query domain, fill age, and historical error rate as features
- Real-world integrations : plugging InferOpt into production chatbot and RAG pipelines to validate savings ratios at genuine traffic volumes
- Research publication : the combination of post-retrieval gap detection, self-improving templates via gap promotion, and confidence-weighted blending doesn't exist as a unified published system; we think it's worth formalizing

Log in or sign up for Devpost to join the conversation.