-
-
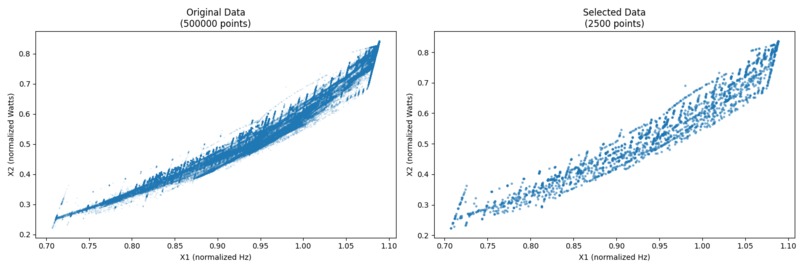
DS1, output
-
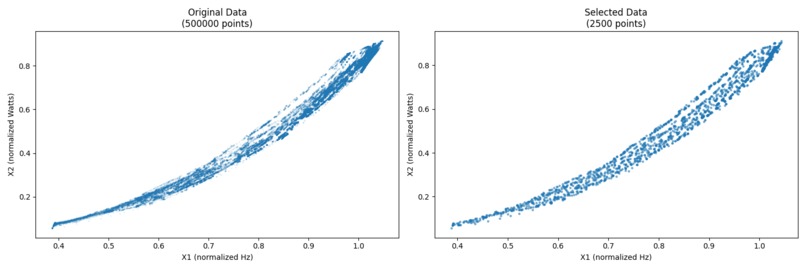
DS2, output
-
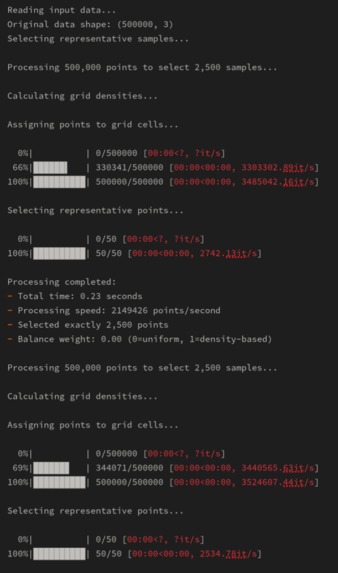
Example running screen with DS1.
-

Propagation and auto-tuning parameter.
-
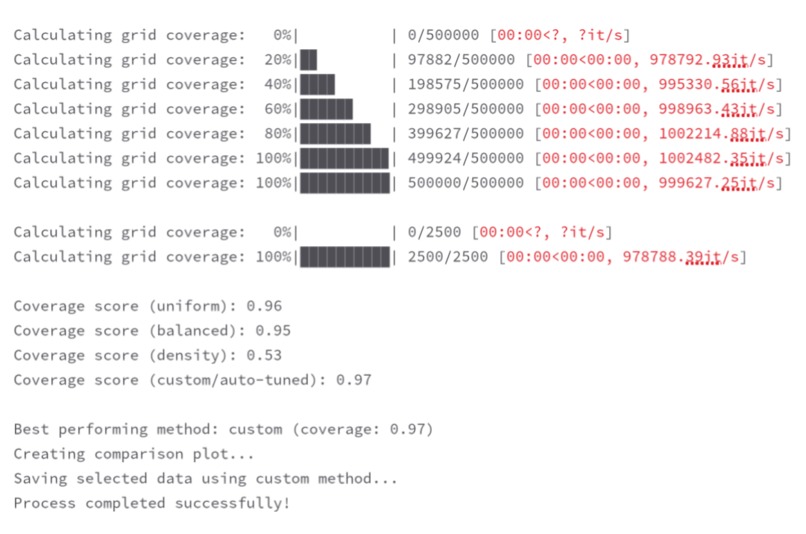
Pick the best parameter.





Inspiration
Baker Hughes sponsors this wonderful event and challenges us to solve a problem. It is a great opportunity to learn and build something useful, while working on real industrial data.
What it does
The task is to downsample point cloud data to reduce the number of points while preserving the overall shape and structure of the data. This solution is elegant and fast, without GPU acceleration.
How we built it
We used a grid-based approach to estimate the density of the data and select representative points. The grid size and balance weight are the main parameters to tune for the desired output.
Challenges we ran into
Initially we settle on a density-based approach as guided, it is highly effective but also extremely slow, citing 2 hours for a 98% coverage. We move on to a smaller density-based approach, which still captures the overall shape but is much faster.
Accomplishments that we're proud of
The speed, the simplicity and the elegance of the solution. It achieves a 96% coverage in definitely less than 30 seconds when running on an Intel CPU i7-13700HX.
What we learned
We learned a lot about the grid-based approach to estimate the density of the data and select representative points. We also learned about the importance of parameter tuning for the desired output.
What's next for Heuristic-oriented Fast Point Cloud Data Downsampling
This iterative tuning of the parameters can be automated, for example by using a grid search or a genetic algorithm, in the end it would be similar to a real machine learning calling back propagation. The storage could also be optimized to SVM, if a move to full Machine Learning is considered.

Log in or sign up for Devpost to join the conversation.