-
-
-
-
-

-
Raindrop Admin: https://svc-01kc6rbecv0s5k4yk6ksdaqyzp.01k66gywmx8x4r0w31fdjjfekf.lmapp.run





About Hakivo
Inspiration
Every year, Congress introduces over 10,000 pieces of legislation. State legislatures add thousands more. Yet if you asked the average American what bill is being debated this week that could affect their rent, their healthcare, or their kids' school, most of us would draw a blank.
This isn't apathy. It's an accessibility crisis.
Here's what sparked the idea: Members of Congress don't read all those bills either. They have legislative aides, staffers who track, summarize, analyze, and flag what matters. Lobbyists have them. Politicians have them. Corporations have entire teams dedicated to monitoring legislation that affects their interests.
Regular citizens? We're expected to figure it out on our own, navigating dense legal language across fragmented government websites, while working full-time jobs and managing the demands of everyday life.
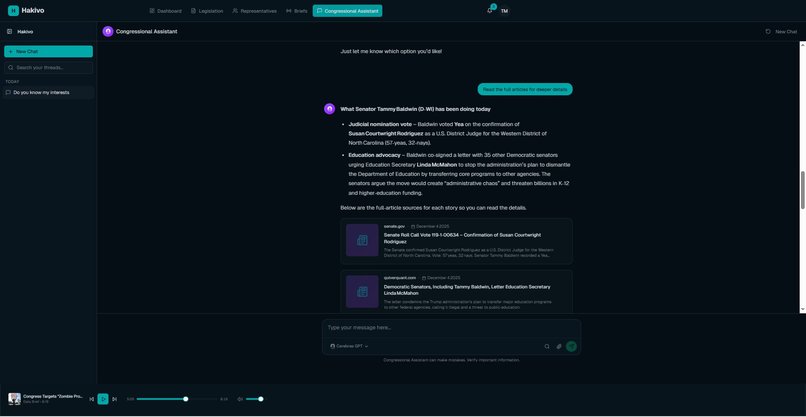
I wanted to change that equation. What if everyone had access to their own personal legislative aide, an AI-powered system that monitors legislation at federal and state levels, translates it into plain language, and delivers personalized briefings you can read, listen to, or explore?
That's Hakivo.
The name comes from two roots: haki, which means "justice" or "rights" in Swahili, and vo, from the Latin vox, meaning "voice." Together, Hakivo means "the voice of justice" or "the voice of rights."
I chose this name because it captures the core mission: democracy works best when every citizen has access to clear, unbiased information about what their government is doing. Hakivo is the voice that translates complex congressional action into something accessible, whether that's through semantic search, AI analysis, or audio briefings you can listen to during your morning commute. No spin. No agenda. Just the facts, delivered with clarity.
The name also reflects a commitment to amplifying diverse voices in civic engagement. Just as Swahili bridges cultures across East Africa, Hakivo aims to bridge the gap between Capitol Hill and Main Street, making democracy accessible to everyone, regardless of background or time available.
Because civic engagement shouldn't require a law degree or a lobbyist's budget.
What I Learned
The Raindrop Framework Changes Everything
Building on Raindrop was a revelation. The ability to compose serverless primitives: Services, Observers, Queues, Tasks, KvCache, SmartSql, SmartMemory, SmartBucket—into a cohesive architecture without managing any infrastructure let me focus entirely on the product.
AI-Native Architecture Requires New Thinking
This wasn't about bolting AI onto a traditional application. SmartSql lets users query congressional data in natural language. SmartMemory gives our Congressional Assistant persistent context across conversations. SmartBucket enables semantic search across thousands of bills.
Government Data Is Messy (But Accessible)
Congress.gov, OpenStates, and FEC APIs provide remarkable access to legislative data, but the formats are inconsistent, the schemas vary by state, and the update frequencies differ wildly. Building reliable data pipelines required more defensive coding than I anticipated.
Voice Changes Everything
Converting briefings to audio using Google Gemini TTS transformed the user experience. Suddenly, civic engagement fits into a commute, a workout, a dog walk. The medium isn't incidental; it's essential to accessibility.
How I Built It
Architecture Overview
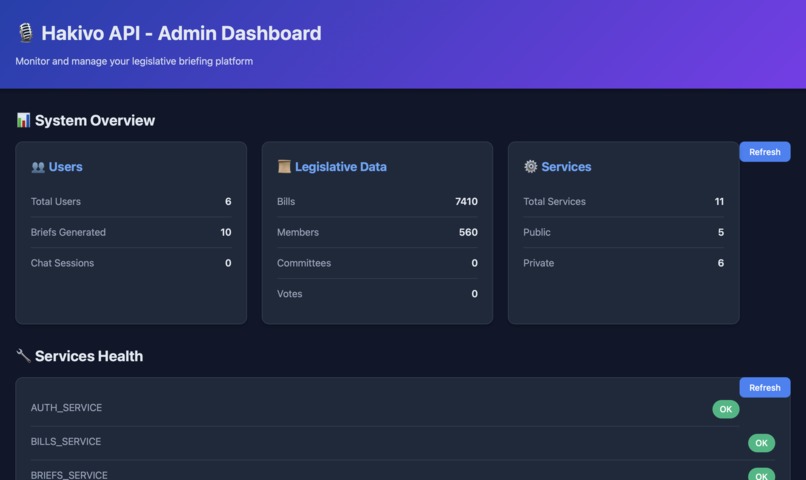
Hakivo is built entirely on the Raindrop framework, with 58 modules and zero infrastructure to manage.
The Core Stack:
- Raindrop Services — 24 API endpoints handling bills, briefs, chat, members, authentication, and dashboard
- Raindrop Observers — 4 event-driven processors for async brief generation, bill enrichment, data sync, and search indexing
- Raindrop Tasks — 8 scheduled jobs for daily briefs, weekly summaries, podcast generation, and data synchronization
- Raindrop Queues — 5 message queues connecting services to background workers
- Raindrop KvCache — 9 dedicated caches for sub-millisecond response times
- Raindrop SqlDatabase — D1 relational database for all core data
- Raindrop SmartSql — Natural language queries on congressional data
- Raindrop SmartMemory — Contextual AI memory for the Congressional Assistant chatbot
- Raindrop SmartBucket — Semantic search across legislation
External Integrations:
- Congress.gov API — Federal legislation, voting records, bill texts
- OpenStates API — State legislature data across all 50 states
- FEC API — Campaign finance and donor information
- Anthropic Claude — Generates Daily Brief and Podcast scripts
- Cerebras — Bill Analysis
- Google Gemini TTS — Voice synthesis for audio briefs and podcasts
- Perplexity — Real-time news integration
- Geocodio — Address-to-district mapping
- Vultr Object Storage — Audio file storage for daily briefs and podcasts
- WorkOS — Authentication and SSO
- Stripe — Subscription management
The Data Pipeline
Congress.gov / OpenStates → Sync Scheduler → Queue → Observer → Database
↓
AI Enrichment Pipeline
↓
SmartBucket Indexing
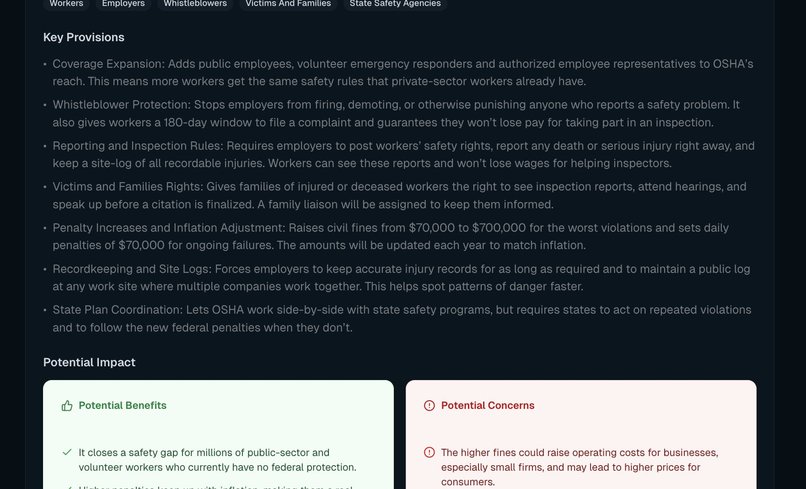
Every day, scheduled tasks pull fresh data from government APIs. Observers process the queue, enriching bills with AI-generated summaries, key provisions, and impact analysis. SmartBucket indexes everything for semantic search.
The Brief Generation System
User Preferences + Location → Brief Queue → Brief Generator (Observer)
↓
Claude Analysis + News Integration
↓
Gemini TTS → Vultr Storage
↓
Personalized Audio Brief
Users set their interests during onboarding. The system generates personalized daily briefs by pulling from their tracked topics, their representatives' activities, and relevant news, then converts them into NPR-style audio they can listen to anywhere.
Challenges I Faced
Challenge 1: No Backup System for Raindrop SQL
This was my most significant pain point. I ingested thousands of bills, representatives, and user records into Raindrop SQL, but there's no built-in way to export, back up, or restore the data. I had to rebuild the backend 3 times during this challenge, including 2 days before the deadline.
During development, I accidentally corrupted the data twice and had to reseed everything from scratch manually. For a production application handling civic data, this created real anxiety. I need peace of mind that user data can be recovered.
What I'd love to see: Scheduled automatic backups, on-demand exports, point-in-time recovery, and CLI commands like raindrop db:backup and raindrop db:restore.
Challenge 2: AI Code Assistants Need Raindrop-Specific Training
I used Claude extensively to help build Hakivo, but it made frequent mistakes:
- Generated code using incorrect Raindrop syntax
- Confused Raindrop primitives with Cloudflare Workers or AWS Lambda concepts
- Hallucinated APIs that don't exist
- Forgot context about my architecture between sessions
I eventually use an open-source tool called Archon to keep Claude on track. A first-party .raindrop-rules or CLAUDE.md file that AI assistants automatically recognize would save hours of frustration.
Challenge 3: Government API Inconsistencies
Congress.gov and OpenStates use different data formats, update frequencies, and error-handling patterns. Building a unified data model required extensive normalization logic and defensive coding for edge cases.
Bills sometimes have missing fields. Representatives change mid-term. Vote records arrive delayed. Every assumption I made about data consistency was eventually violated.
Challenge 4: Voice Generation at Scale
My original plan used ElevenLabs for voice synthesis, but I exhausted my credits during development. Pivoting to Google Gemini TTS mid-project required reworking the audio pipeline—but ultimately delivered reliable, cost-effective voice generation at scale.
Challenge 5: Making Legislation Actually Understandable
The most complex challenge wasn't technical—it was linguistic. Legal language is dense by design. Translating bills into plain English without losing accuracy or introducing bias required extensive prompt engineering and iterative refinement of Claude's analysis pipeline.
The goal isn't just summarization. It's genuine comprehension. A user should finish reading a brief and actually understand what a bill does and why it matters to them.
What's Next
Hakivo is just the beginning. Future plans include:
- Civic Action Integration — Not just information, but pathways to action: contact your representative, submit public comments, find town halls
- Community Features — Connect with neighbors tracking the same issues
- Expanded State Coverage — Deeper integration with municipal and county-level legislation
- Accessibility Enhancements — Multiple languages, screen reader optimization, simplified reading levels
Democracy works when people participate. Hakivo removes the barriers.
Built for the Liquid Metal AI Championship Hackathon Categories: Best AI Solution for Public Good
Built With
- and-integrates-with-**congress.gov-api**
- congressapi
- deployed-on-**netlify**-with-**netlify-functions**
- fec-api**
- geminitts
- geocodio**
- google-gemini-tts**-for-voice-synthesis
- kvcache
- netlify
- nextjs
- observers
- openstates
- openstates-api**
- perplexity
- perplexity**
- powered-by-**anthropic-claude**-and-**cerebras**-for-ai-analysis
- queues
- raindrop
- smartbucket)
- smartmemory
- smartsql
- sqldatabase
- tasks
- vultr-object-storage**-for-audio-file-delivery
- workos**




Log in or sign up for Devpost to join the conversation.