-

probability-based data optimization
-

our problem, the solution using VLMs.
-

abstraction of the models.
-

GFLOW net, model 1.
-
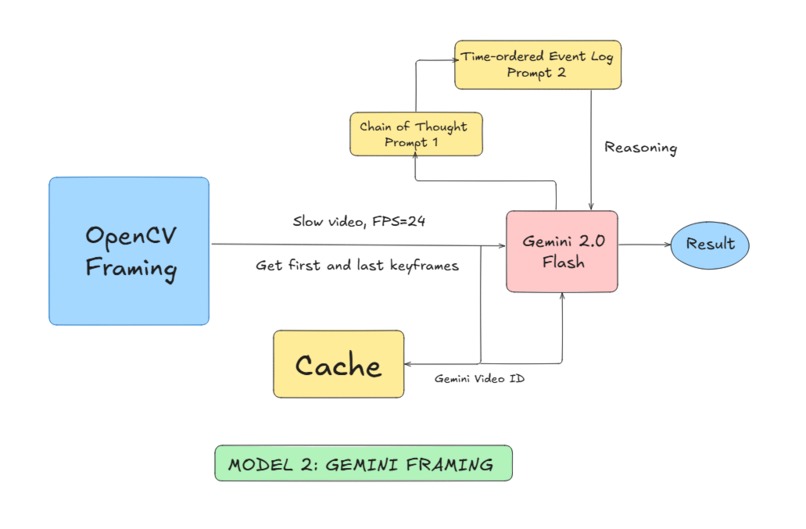
Gemini framing, model 2.
-
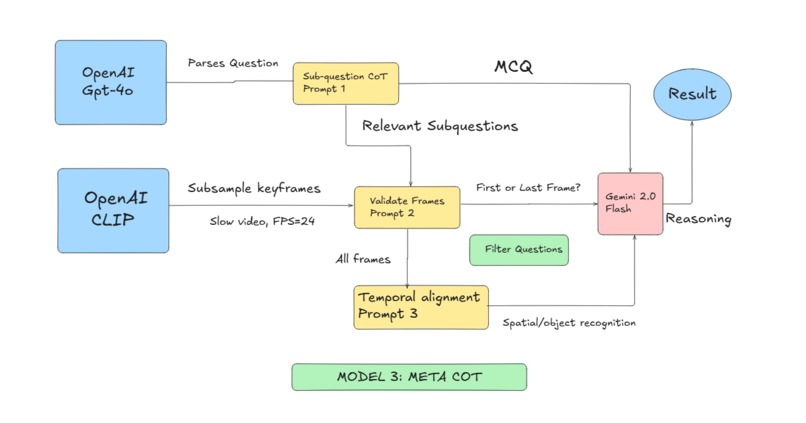
Meta COT, model 3.






Inspiration
We tackled the Tesla Real-World Video Q&A challenge, excited to take on a real-world ML problem. Some of us had experience with AV perception systems and cognitive modeling and were excited to develop reasoning with VLMs.
We approached this as both a research initiative and an engineering problem: there was a need to read literature and ideate a novel solution since reasoning with vision models remains an unsolved problem. But there was also a requirement to build robust, computationally efficient algorithms to tackle our latency and resource bounds.
After much exploration, we settled on a two-step prompting pipeline that utilizes time-stamped event logging, data caching, and structured data formation to address the challenge.
The Problem
The challenge: Given a 5-second clip recorded from the perspective of ego, a vehicle with mounted data capture sensors, and a multiple choice question, our model should output the appropriate answer.
The results are visible in the Kaggle competition available at https://www.kaggle.com/competitions/tesla-real-world-video-q-a/leaderboard
A model like this should be able to reason about the objects in the environment and its own position/movement relative to others in the surrounding. It is a crucial first step in developing real-time large-action models, which can understand real time natural language commands and immediately execute their actions based on real-time contextual understanding. A model like this would behave like a large foundational model that can take in data (in the form of raw video frames, RADAR/LiDAR sensor data, GPS + IMU numerical data) and output a course of action. It moves away from the traditional, almost Agentic AI, approach of preprocessing large amounts of sensor data and making sense of individual components using a series of smaller models. Self-driving companies like Tesla would benefit greatly from such an autonomous pipeline.
How we built it / Our Model
We explored different techniques to reason about visual data, which included obtaining textual and numerical encodings from multi-modal foundational language, developing hard-coded agents for object detection and distance estimation tasks, and utilizing Meta Chain-of-Thought reasoning and employed them.
We utilize OpenCV to slow the video and scale it to 24FPS and create 8 image frames constructed from the video. We store the video ID, the image frames, and slowed video in a cache to reduce latency. Passing the individual frames to Gemini 2.0 Flash, we prompt it to generate sub questions relevant to the main question for chain of thought reasoning later. Then, generate a contextual description of the environment for the frames and create a time-ordered event log based on a SS:MS format. However, if the first or last frame of the video can solve the question, only focus on these frames to reduce latency. Using the contextual description and time-ordered event logs, we take encoded text and video embeddings from OpenAI CLIP model from each of the frames and a LLAVA-Video fine tuned model trained from an open-source dataset. These image frames are grabbed from the cache and not parsed by the models. This is passed into a GFLOW NET, which generates the most likely solution from the MCQ by mapping all possibilities based on likelihood of success. Using the reasoning from Gemini 2.0 Flash to generate a definite answer to the MCQ and a GFLOW NET as a verification method, we can achieve high accuracy and low latency through image frames and statistical modeling.
We can compute our model for a given video and question in 6.7 seconds.
Kaggle Links
https://www.kaggle.com/felixngfenda
Challenges we ran into
One of the biggest hurdles we faced was familiarizing ourselves with Vision-Language Models (VLMs) and understanding the extent of their computational capabilities. Downloading the models, running inference on our training dataset, and evaluating the reasoning performance was rather tedious. Another major challenge was optimizing latency using the Nvidia Jetson. While we successfully set up the hardware, we faced permission errors, dependency conflicts, and import mismatches which made using the system challenging. Additionally, integrating multiple models led to compatibility issues, because they had different input-output formats and underlying architectures. Some couldn't work with certain modalities whilst others needed feature representation to be in certain dimensions (which would overhaul the rest of the architecture). Lastly, our dataset was a significant limitation. We were only given access to 50 5-second video unlabelled clips. This meant that we spent a decent amount of time manually annotating correct answers for each question. In many cases, the MCQ answers were ambiguous, and that made it more difficult to evaluate the performance of the model.
Accomplishments that we're proud of
Despite these challenges, we're really proud of what we accomplished—especially since we tried to encode reasoning into vision models, which is an unsolved problem. We weren’t deeply familiar with the architecture and working with a small, messy dataset made the problem more challenging. And yet we were able to reason to a certain degree of accuracy about the environment ego was in.
We also experimented with a range of techniques like prompt engineering, chain-of-thought reasoning, inference with various multi modal models, and novel approaches like using G-flow nets.
What we learned
How to analyze datasets and ideate solutions How to set up compute on NVIDIA jetson hardware How to perform rapid inference using different pretrained models
Tools Used
OpenAI CLIP, Gemini 2.0 Flash, OpenAI GPT-4o, OpenCV, Pandas, NumPY, LLAVA-Video
What's next
We would like to continue developing reasoning capabilities in VLMs. This time around, we were limited by time and knowledge of existing model architectures and pre-trained models for the autonomous use case. Going forward we would like to begin by fine tuning on our own dataset, incorporating various modalities like LiDAR, depth, GPS, and IMU data, and work with other novel methods of image and textual embeddings.


Log in or sign up for Devpost to join the conversation.