-
-

Simple Chat Prompting Interface
-
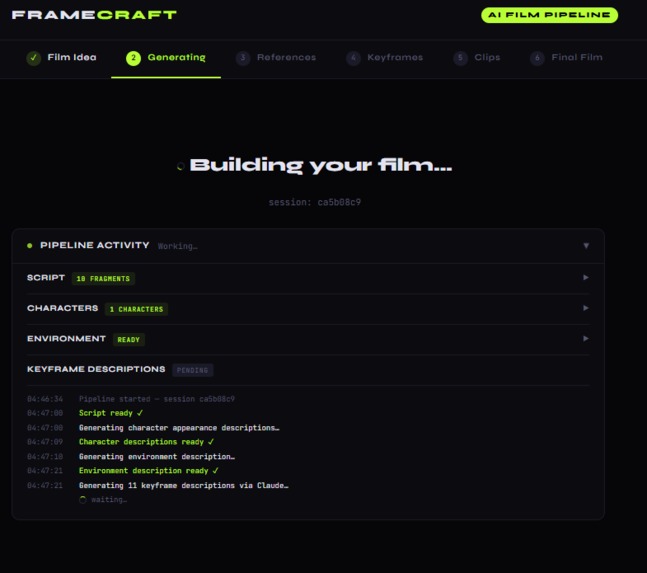
Breaks down generated scripts and descriptions
-
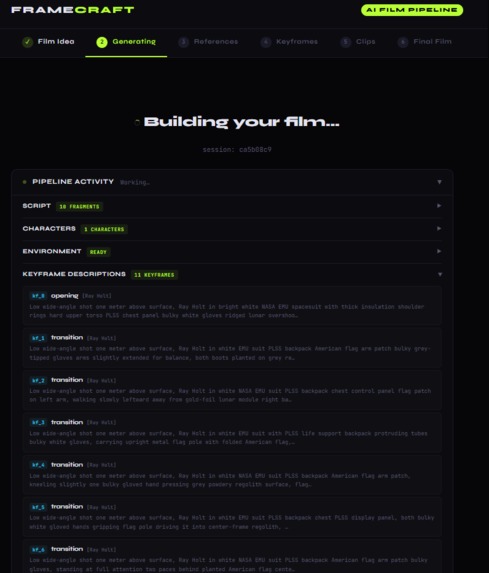
Generates keyframe descriptions for video partitioning
-
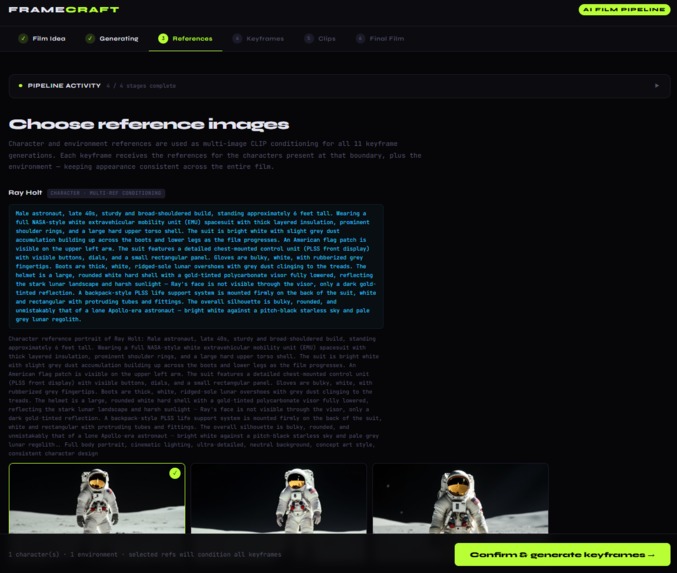
Character variety for user preference
-
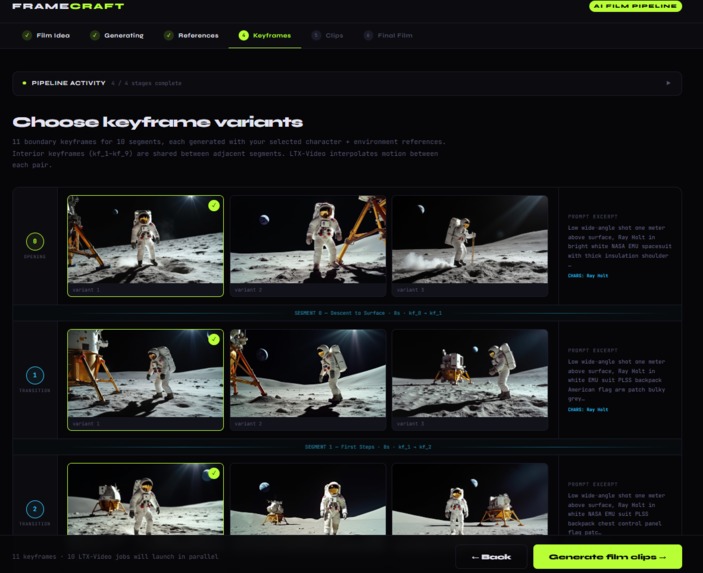
Keyframe variability for user input
-
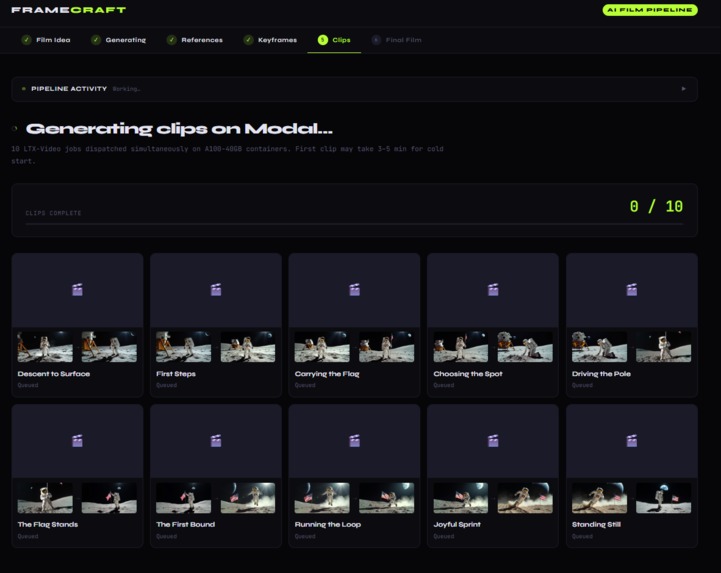
Generates separate videos using FFLF model given keyframes
-
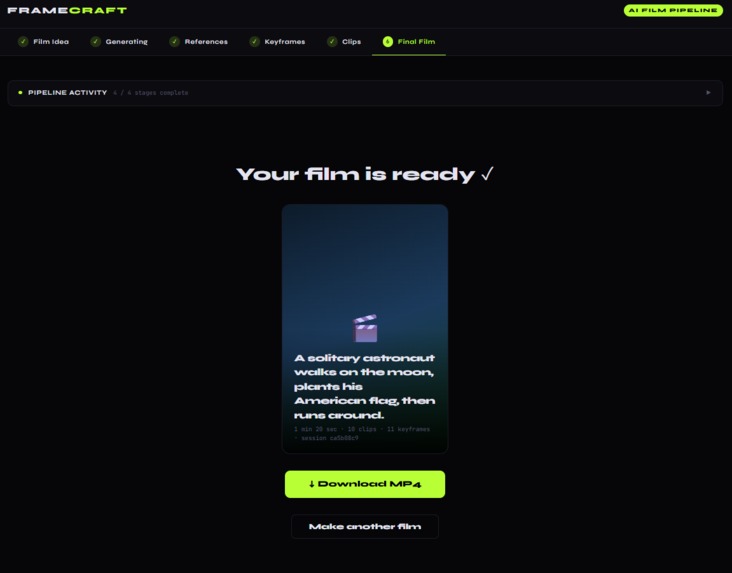
Download your video to watch!







Inspiration
We have all seen AI-generated short-form content on social media, but is it possible to make coherent long-form content with a single prompt?
This is what we wanted to explore for our project: can you go from a one-sentence idea to a fully rendered short film with consistent characters, coherent scene transitions, and real cinematic motion, all automated?
Existing text-to-video tools generate isolated clips with no narrative structure, inconsistent characters, and no user control over the visual direction. We set out to build a full film pipeline that solves all three.
What it does
FilmStitch is an end-to-end AI film pipeline. You type a film idea, and it produces a ~80-second short film with no manual editing or prompting. The pipeline runs in three phases, each pausing for creative user input before continuing.
Phase 1 — Writing and reference generation:
- Writes a 10-segment script via Claude Sonnet, structured with narration, action, dialogue, and per-segment character tracking
- Generates detailed visual character descriptions via Claude — specific clothing, hair, facial features, and build that an image model can reproduce consistently
- Generates a unified environment description via Claude — lighting, materials, color palette, and atmosphere
- Produces 11 boundary keyframe descriptions, with character appearance details embedded directly into each FLUX prompt for consistency
- Renders character and environment reference images (3 variants each) on Modal using FLUX.1-dev
→ User checkpoint: choose preferred reference variants for each character and environment
Phase 2 — Keyframe image generation:
- Renders 33 keyframe images (11 × 3 variants) on Modal using FLUX.1-dev, with multi-reference CLIP conditioning — the character and environment refs relevant to each keyframe boundary are averaged into a single embedding and blended into FLUX's pooled text embedding
→ User checkpoint: choose preferred keyframe variant for each of the 11 boundary frames
Phase 3 — Video and assembly:
- Interpolates 10 video segments in parallel using LTX-Video-0.9.5 on Modal, with first-frame and last-frame conditioning pinning the chosen keyframes at each end of the clip
- Assembles the final film with ffmpeg concat
How we built it
- Orchestration: Python async pipeline (
pipeline.py) coordinating four separate Claude API calls and three rounds of Modal GPU jobs across three distinct phases - Script generation: Claude Sonnet produces a structured JSON script with per-segment character tracking and environment tagging
- Character + environment descriptions: Two additional Claude calls extract detailed, camera-ready visual descriptions before any image generation begins — this is what makes FLUX prompts specific enough to produce consistent character appearances without fine-tuning
- Keyframe descriptions: A fourth Claude call uses those descriptions directly, embedding specific clothing and appearance details into every keyframe prompt rather than relying on the model to infer them
- Image generation: FLUX.1-dev on Modal (A100-40GB). Multi-reference CLIP conditioning: for each keyframe, we encode all character refs present at that boundary plus the environment ref, average their embeddings, and blend the result (30%) into FLUX's pooled text embedding. The full cinematic prompt routes through FLUX's T5 encoder, which has no token length limit
- Video generation: LTX-Video-0.9.5 on Modal (A100-40GB) via
LTXConditionPipeline. Dual-frame conditioning pins first and last frames usingLTXVideoConditionobjects; intermediate motion is guided by the segment's narration and action text. 10 segments dispatch concurrently withconcurrency_limit=10, running on separate containers simultaneously - Server: FastAPI with WebSocket for real-time progress streaming across all three phases. Three new endpoints handle the phase boundaries:
/pipeline/start,/pipeline/{id}/gen-keyframes, and/pipeline/{id}/continue - Frontend: React SPA with a step-by-step wizard — idea input → live pipeline log → reference picker → keyframe timeline with per-boundary variant selection → parallel clip progress grid → final download
- Assembly: ffmpeg concat demuxer for gapless segment joining, with re-encoding for codec consistency across clips
Challenges we faced
CLIP's 77-token hard limit in the IP-Adapter path. FLUX has two text encoders: T5-XXL for the main prompt (handles ~512 tokens, drives image quality) and CLIP for pooled_prompt_embeds (hard 77-token ceiling). Our character conditioning code called encode_prompt() with the full keyframe prompt to get the CLIP pooled embedding for blending. Prompts longer than 77 tokens were silently truncated, producing a conditioning signal derived from a mangled version of the prompt. The fix passes a 50-word summary to encode_prompt() while the full prompt still travels through T5 via the main pipeline call — two separate paths, independently controlled.
Cold start latency. First LTX-Video container spin-up downloads ~10 GB of weights and takes 3–5 minutes. We mitigated this with min_containers=1 on both Modal classes.
Character consistency across keyframes. Pure text-to-image generation produces wildly different character appearances across 11 separate generations. We tried three approaches: text-only (poor), single character reference with CLIP blend (significantly better), and averaged multi-reference conditioning including environment (current, best). True per-subject IP-Adapter attention injection would require deeper pipeline surgery and is on the roadmap.
Why Modal?
The pipeline needs burst GPU compute — 33 FLUX image generations followed by 10 LTX-Video generations, then nothing until the next film. Traditional GPU provisioning (reserved instances) would be extremely wasteful. Modal provides:
- Pay-per-second billing — only charged during active inference
- Auto-scaling — spins up containers on demand, scales to zero when idle
- Persistent volumes — model weights cached across invocations (flux-weights, ltx-weights volumes)
- Horizontal scaling —
max_containers=10for LTX-Video means 10 parallel A100s during video generation
What we learned
- The N+1 keyframe model (11 boundaries for 10 segments) is a clean abstraction for narrative video — shared transition frames naturally enforce visual continuity without any explicit stitching logic
- Generating character descriptions as a dedicated Claude step before image generation — rather than relying on the image model to infer character details from a brief name — dramatically improves consistency across long generations
- Separating the pipeline into three explicit phases with user checkpoints between them is the right UX model for generative workflows: it catches bad reference or keyframe choices before the expensive video generation step, saving significant time and cost
Example
Check out this video generated by a simple prompt "a stranded astronaut on the moon walks around and discovers nature"! https://youtu.be/FUdKMRBkudo
What's next
- Better character consistency: replace averaged CLIP blending with proper per-subject IP-Adapter attention injection
- Environment conditioning in video: pass the environment reference image to LTX-Video as an additional style conditioning signal to maintain visual consistency in background elements across clips
- Audio pipeline: narration from segment dialogue + ambient sound generation synced to clip timing
- Inpainting checkpoint: allow users to edit individual keyframe regions before video generation begins, fixing issues like wrong character position or background elements
- Longer films: hierarchical scene planning (acts → scenes → segments) to support 5–10 minute narratives with consistent world-building
- Higher resolution output: decoding optimizations to push LTX-Video to 1024×576 without OOM on A100-40GB






Log in or sign up for Devpost to join the conversation.