-

Dashboard
-
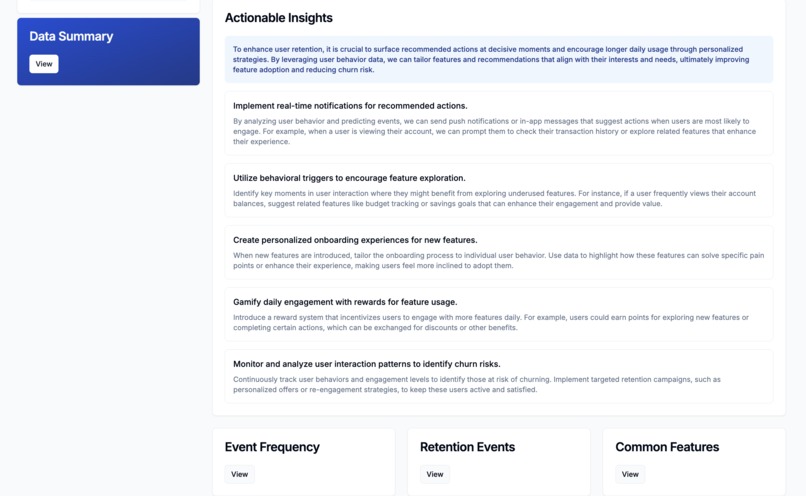
Actionable Insights
-
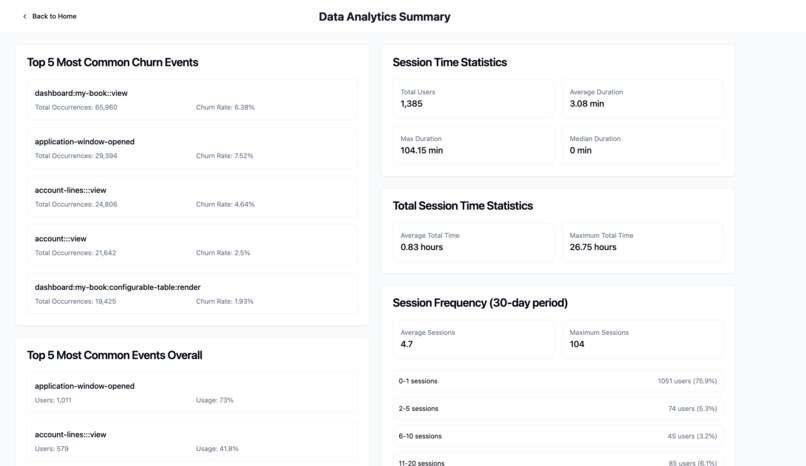
Overall Data Summary (Part 1)
-
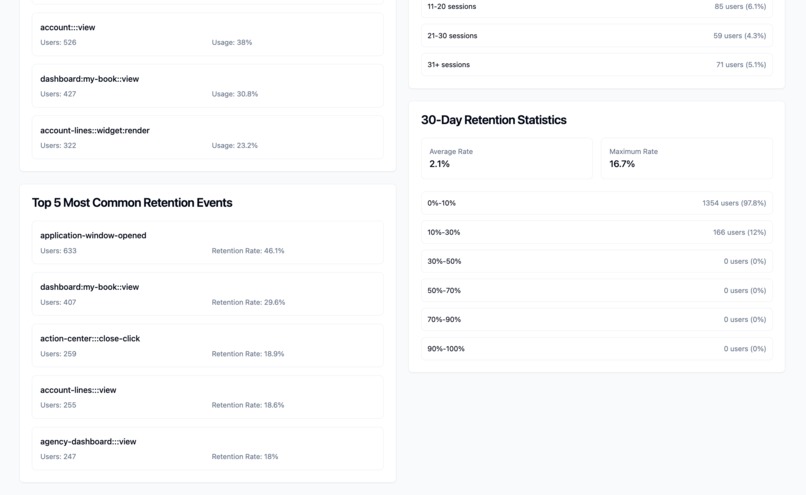
Overall Data Summary (Part 2)
-
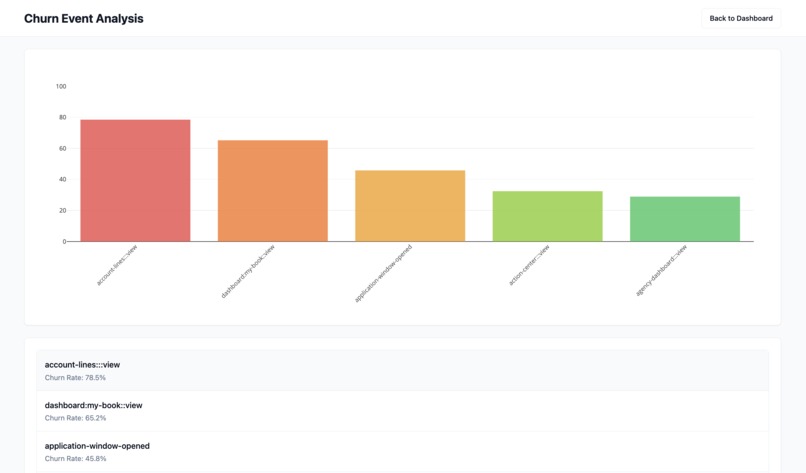
Churn Event Analysis (for a specific user)





Goal 🎯
As part of Federato's Challenge track, teams were tasked with 3 main objectives:
- Exploring and analyzing user behavior data to understand how different actions impact engagement and retention
- Developing an Optimization Framework for Next-Action Recommendations
- Providing Actionable Insights for Federato's Platform Improvement
After preliminary analysis, we decided to build a fully integrated AI-powered recommendation system that intelligently suggests the best next actions based on user behavior, optimizing engagement and efficiency. Inspired by recommendation engines and AI-driven automation, we set out to create a solution based on rigorous mathematics and modelling strategies that personalizes user journeys in a seamless and intuitive way.
How We Designed our Model
Our model is a custom designed Deep Learning Neural Network based on Sparse Graph Attention Networks and Minimized GRU models (Sparse GAT-MinGRU) to contextually understand spatiotemporal information. By representing different events as nodes, we have leveraged the powerful graph-based learning of Graph Neural Network architecture to understand relationships between different user events and sequential learning of GRU models, allowing the model to output the 3 most likely events a user would mostly likely take the action as well as the time needed to navigate to the next event. In an optional fine tuning layer, specific users can be added to the model to create personalized actions for the user.
The model architecture we've chosen encapsulates and combines multiple next-action approaches:
- Predictive guy modelling: Our GAT-MinGRU model is inspired by previous literature with similar that have had high accuracy in predicting traffic. The idea of incorporating temporal layers into our analysis came from: "A ship trajectory prediction method based on GAT and LSTM" (Zhao J. et al., Dec 2023) as well as
- Graph-based analysis: Our GNN architecture effectively identifies relationships between event nodes, identifying common interactions and pruning unimportant nodes in its learning process using Dropoff.
- Causal Inference: Taking inspiration from Transformer architecture, GAT architecture incorporates attention heads that help identify and give more weight to user actions that provide more impact on next actions. Our hyperparameter tuning has also given more bias to events that are not churn events but rather high retention events.
Some features about how we built our Model:
- Relatively inexpensive computationally due to usage of Sparse Edge Matrices and Minimal GRU model (1000x cheaper than GRU models, with 22% of parameters needed compared to GRU)
- Achieved 86.7% accuracy on our testing sets after 20 epochs (we weren't able to train to more layers in time)
- Scalable architecture by changing events to vector embeddings allows for future events added to be predicted based on event name context
- The attention weights of our model can be detached to understand high impact nodes and give insight into how the GAT portion of our architecture understands data.
- Model architecture contains 1 Embedding Layer, 1 GAT Layer, 2 MinGRU Layers, Output Layer.
What Use is A Model That is Hard to Understand? 🧐
Models that can predict but whose predictions can't be leveraged are useless.
The true value lies in how we use these predictions to increase retention and reduce churn. To do this, we've integrated the predictions into an LLM pipeline which takes in important statistics including: common features used, common churn events, new features with low feature penetration that we want to improve user usage upon, as well as many more. This achieves personalized recommendations that not only identify the moments when users are most likely to drop off, but also suggests recommendations for how to combat this.
Data-Driven Framework 📈
To deal with the issue of increasing retention, we've developed the following framework:
Step 1: Identifying Churn Events with AI Using our model to continuously monitors user behavior, we can predict when a user is likely to disengage. This is based on:
- Historical churn patterns (e.g., inactivity periods, abandoned workflows, incomplete tasks) 2, Sequential event analysis (predicting the likelihood of exit based on prior actions)
- High-impact engagement features (understanding what keeps users retained) The model outputs 3 outputs for the suggested next event. If the highest probability is a churn event/exit event, the next step is triggered.
Step 2: LLM-Driven Retention Strategies Once a churn event is identified, our LLM module generates context-aware recommendations based on user behavior. It takes into account:
- Common churn events (identified from data)
- Frequently used features (leveraging insights on what successful users engage with)
- Underutilized features (nudging users toward beneficial but overlooked functionalities)
- Personalized user context (adapting to the specific user’s journey)
For example:
- ✅ Long Periods of Inactivity → Trigger a targeted reminder highlighting relevant features or recent activity.
- ✅ Abandoned Task Flows → Recommend completion incentives or shortcuts to resume the task seamlessly.
- ✅ Exit Intent Detected → Provide a last-minute intervention, such as alternative actions, success stories, or feature tutorials.
Step 3: Dynamic Optimization & Feedback Loop Our system doesn’t just suggest actions—it learns from their impact. By tracking which interventions successfully retain users, we refine both the predictive model and LLM suggestions over time. We leave this part of the framework to be implemented as it depends on specific initiatives that depend on Federato's specific retention campaign objectives.
- Success Metrics Tracking → Analyzing which recommendations lead to engagement vs. continued churn.
- Adaptive Learning → Our fine tuning layer allows the model’s weighting for different churn signals to be adjusted based on real-world effectiveness and new approved high-quality data..
- Federato API Integration → Seamlessly incorporating next-action recommendations within the platform.
Impact: Turning Predictions into Retention By integrating predictive AI with real-time recommendations, Federato can proactively address user churn rather than reacting after the fact. This allows for:
- 🚀 Personalized engagement at the exact moment a user needs guidance.
- 📊 Data-backed feature adoption through nudges that improve underutilized tool usage.
- 🔁 Continuous optimization ensuring that retention strategies evolve with user behavior.
With this framework, Federato not only predicts churn but actively prevents it, driving long-term user retention and engagement.
The user interface we've provided allows the simulation of a sequence of user events—essentially, a set of actions representing a user interacting with the platform or a series by batch uploading user information. Our model will predict the next action, whether it’s the user staying, leaving, or interacting with something else. This helps visualize how the model reacts to real user behavior, and can provide insight into how to improve user engagement in real-world scenarios.
Challenges we ran into 🚧
Handling Large Data Sets: The dataset we worked with had over 15 million rows, making it a challenge to efficiently process and store the data. Ensuring we could maintain performance without compromising on accuracy required a lot of optimization and testing. We had to implement techniques like data sampling and batch processing to ensure our model could scale.
Building the Model: Constructing a robust GAT + LSTM model was a complex task. Reducing the computation time for our model was a large portion of our workload–reading papers on mini-batching, accurate weighted sampling techniques, and choosing between embeddings and encodings. The biggest challenge was fine-tuning the architecture to properly capture sequential dependencies in user actions, while still being computationally efficient. Additionally, training the model required us to carefully balance overfitting with underfitting, especially when dealing with sparse data.
Prediction vs. User Engagement: Integrating predictions into the user engagement pipeline and making them actionable without disrupting the user experience was tricky. We needed to ensure the predictions were useful and not disruptive, maintaining user flow while also guiding them toward meaningful next steps.
Accomplishments that we're proud of 🌟
In-Depth Data Analysis: We performed comprehensive analysis on the dataset, identifying key metrics such as top retention events and top churn events. This data provided valuable insights into user behavior patterns, helping us understand which actions or features are most likely to influence retention.
Session Analytics: We were able to calculate important session statistics like total session time and average session time, which gave us a clearer picture of user engagement. These metrics are not only important for understanding how users interact with the platform but also for informing future improvements and optimizing user experience.
Effective Visualization: We created meaningful visualizations that helped stakeholders quickly grasp key trends in user retention and engagement. This makes it easier to identify problem areas and opportunities for user engagement optimization.
What we learned 💡
Data Preprocessing is Key: Given the large volume of data, we learned that preprocessing is just as important as the modeling phase. Cleaning the data, identifying the relevant features, and ensuring it was structured in a way that the model could interpret were all crucial steps.
User-Centric Development: By integrating our predictions directly into user flows, we learned the value of contextual recommendations. This process made us realize how important it is to tailor solutions to users’ behaviors, rather than just predicting a generic outcome.
What's next for Federato Data Challenge ⏭️
Further Fine-Tuning: There were quite a few hyperparameters we left mostly untouched as part of our model and academic literature has shown us that it is quite possible to train our model to >95% accuracy (including parts of our loss functions, changing the number of layers, and changing our input parameters to help provide better contextual information). Furthermore, we weren't able to include all the techniques in all the papers we read that helped improve accuracy (e.g. L0 regularization to increase sparsity)
Retraining Model on Higher Quality Data: Even after filtering out many parameters and data points we found weren't useful for the model, we found the model we trained was still biased towards a couple outputs due to uneven representation of certain unproductive data points.
Literature Referenced
- Graph Attention Networks
- A paper we read later on to reduce our training time and compute: Sparse Graph Attention Networks
- Inspiration for Spatiotemporal design: A ship trajectory prediction method based on GAT and LSTM
- MinGRU: Were RNNs all We Needed?
- Learning Mini-Batching for the first time to handle Big Data: Kaggle: Mini-Batching
- Amazing Stanford Lecture in Understanding GNNs (https://www.youtube.com/watch?v=-UjytpbqX4A&ab_channel=LindseyAI)
- Dynamic Sparse-Matrix Allocation on GPUs
- Neuron-Specific Dropout: A Deterministic Regularization Technique to Prevent Neural Networks from Overfitting & Reduce Dependence on Large Training Samples
Built With
- flask
- gat
- ipynb
- mingru
- next
- postgresql
- python
- react
- supabase





Log in or sign up for Devpost to join the conversation.