-
-
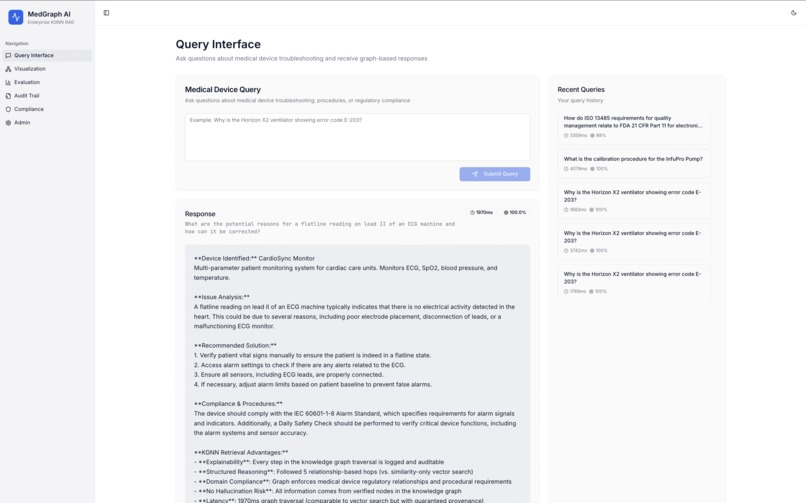
Inserting a Query
-
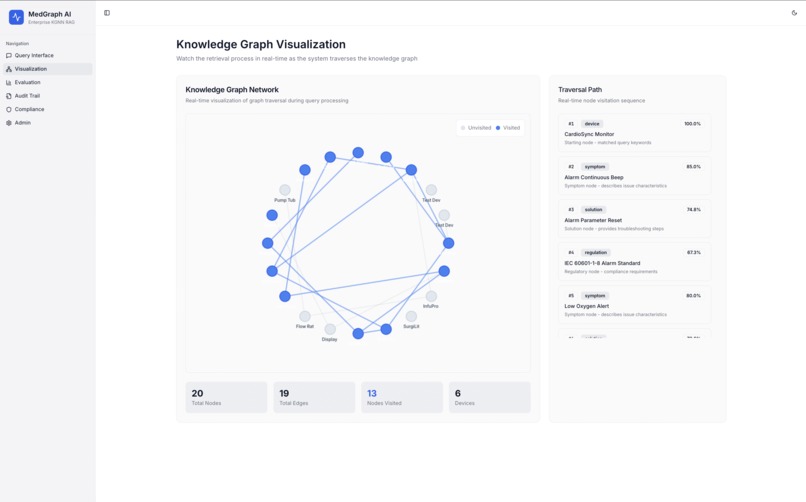
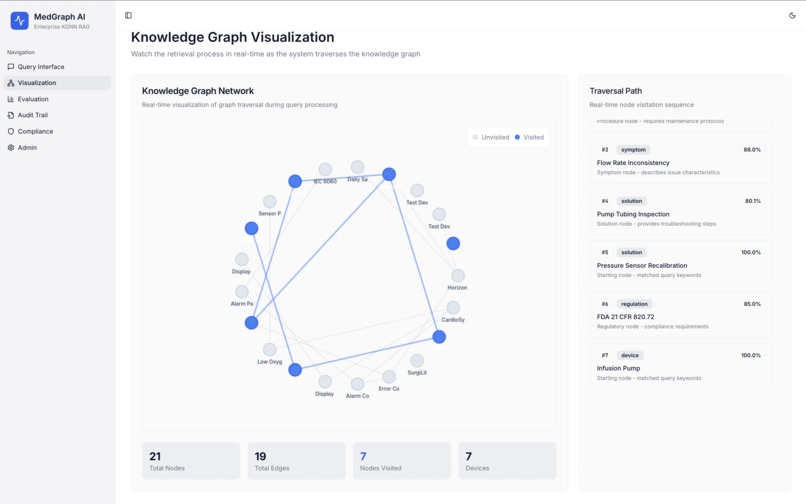
Knowledge Graph Visualization
-
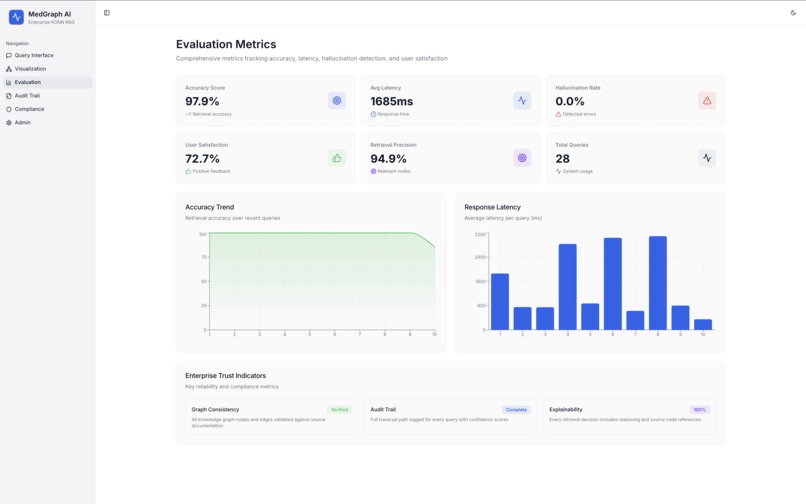
Evaluation Metrics
-
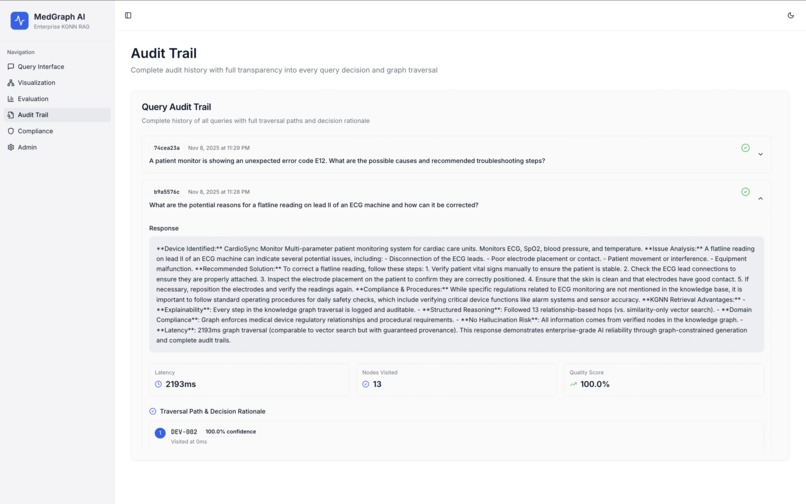
Review All Previous Queries
-
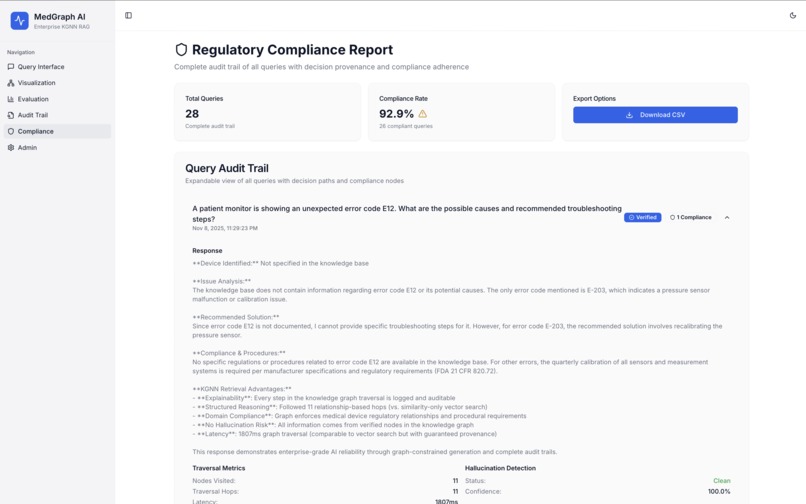
Compliance Reports for All Queries
-
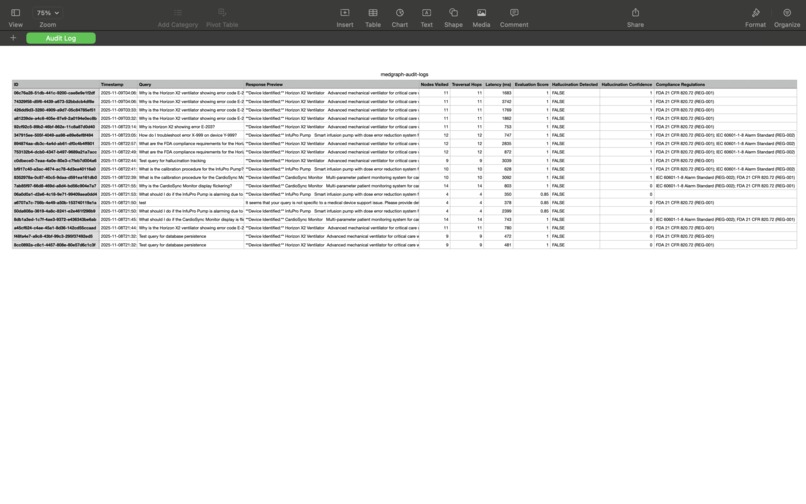
Printable Compliance Report for Queries
-
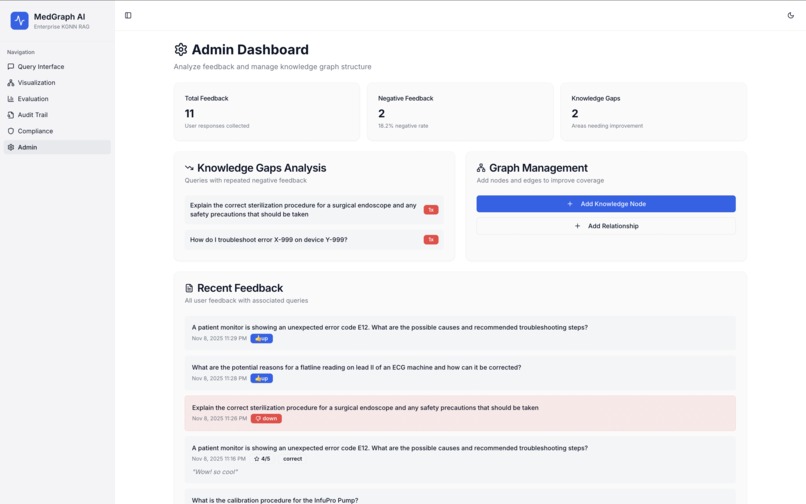
Review Adim Dashboard for Feedback, Knowledge Gaps, and Additions
-
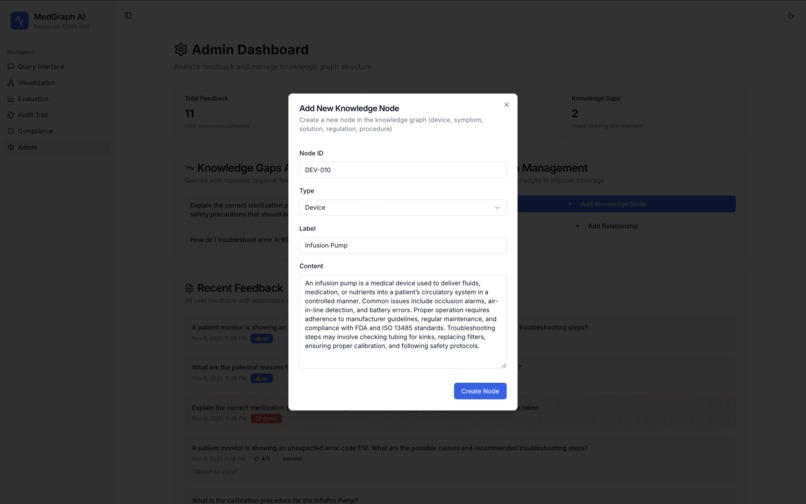
Add New Node
-
Node Appears on Knowledge Graph









Inspiration
As AI becomes deeply embedded in enterprise systems, trust and reliability have emerged as the biggest barriers to real-world adoption. We were inspired by the growing need for AI systems that don’t just perform well in benchmarks but can be trusted in production. During our brainstorming, we kept coming back to one question: How can we make AI outputs explainable, verifiable, and auditable so humans can truly trust the system’s reasoning? This challenge motivated us to build a solution that bridges graph-based reasoning and retrieval-augmented intelligence, enabling AI models to justify their decisions through transparent, interpretable structures. We wanted to move beyond black-box predictions and design something that could help enterprises see why an AI made a choice, trace how information was used, and ensure compliance and reliability in high-stakes environments. In short, our inspiration came from the belief that AI shouldn’t just be powerful; it should be accountable.
What it does
1. Query Interface
Submit medical device troubleshooting queries:
- "Why is Horizon X2 showing error E-203?"
- "How do I calibrate the MediPump Elite?"
- "What FDA regulations apply to ventilator alarms?"
The system will:
- Traverse the knowledge graph to find relevant nodes
- Display the real-time traversal path
- Generate a response using only verified information
- Show confidence scores and compliance requirements
- Detect any potential hallucinations
2. Knowledge Graph Visualization
Interactive canvas showing:
- Blue nodes - Medical devices
- Orange nodes - Symptoms and error codes
- Green nodes - Solutions and procedures
- Purple nodes - Regulations and compliance requirements
- Weighted edges - Relationship strengths
3. Evaluation Metrics
Real-time dashboard displaying:
- Total Queries processed
- Average Latency
- Accuracy Rate
- Hallucination Rate
- User Satisfaction
4. Audit Trail
Complete query history with:
- Query text and timestamp
- Full traversal path (nodes visited in order)
- Response generated
- Confidence scores
- Hallucination detection results
- User feedback (if provided)
5. Compliance Reporting
Regulatory audit tools:
- Filter queries by regulation type
- View complete decision provenance
- Export to CSV for FDA submissions
- Track compliance coverage
6. Admin Dashboard
Knowledge graph management:
- Feedback Analysis - Total/negative feedback counts
- Knowledge Gaps - Queries with repeated negative feedback
- Add Nodes - Create new devices, symptoms, solutions, regulations
- Add Relationships - Connect nodes with weighted edges
- Recent Feedback - Review user ratings and comments
Why It Matters
1. Better accuracy and reasoning
Traditional RAG systems often just retrieve text chunks using vector similarity and feed them into an LLM. That works okay for simple queries, but when you need multi-hop reasoning (connecting multiple concepts, summarizing complex relationships), the flat retrieval can miss the relational structure. Using a knowledge graph helps capture the relationships between entities, making it easier to answer more complex queries that involve “how things relate” rather than just “what is this”. For example: “If a patient has condition X and medication Y, what interactions or follow-ups should be considered?” A KG can encode “medication Y treats condition Z”, “condition X is risk factor for Z”, etc.
2. Traceability / auditability
In domains such as healthcare, finance, law etc., you often need to know why a system arrived at a certain output (for compliance, explanation, liability). A KG + RAG system can provide the retrieval path (which graph nodes/edges were used), the original sources, etc. This supports transparency and helps build trust in the outputs. Knowledge graphs and retrieval augmented generation reduce hallucinations because the output is grounded in structured, verifiable knowledge.
3. Handling complex, interconnected data
Many enterprise data scenarios are not just independent documents but networks of information (people, projects, contracts, regulations, events) with many relationships. A KG helps model those networks. Then retrieval can traverse relevant paths rather than simply fetching contiguous text. That’s important when relationships matter (for example: compliance across multiple contracts, diagnosing a patient with overlapping conditions).
4. Reducing hallucinations and irrelevant context
One challenge of LLMs is they can “hallucinate” (fabricate plausible-looking but incorrect information). If one feeds them retrieved text that is loosely relevant, they may still hallucinate or mis-reason. If instead you feed them a well-structured subgraph of related entities/relationships that are strongly relevant to the query, the LLM is less likely to go off-track. Also, by providing the retrieval path from the KG, you can validate and prune irrelevant context.
5. Domain adaptation and controlled knowledge
A KG allows you to encode domain-specific ontologies, vocabularies, controlled relationships (e.g., medical terminologies, drug-disease interactions). For specialized domains, this is critical. A generic LLM may know general knowledge, but when you integrate a custom KG, you can tune it for your enterprise’s knowledge, ensuring more reliable outputs.
What's Next
Phase 1: Strengthen Core Reliability & Observability
- Drift Monitoring: Track changes in graph data distribution, retrieval relevance, LLM output distributions over time.
- Hallucination Detection: Build a module to flag outputs that appear unsupported by the graph context (e.g., “unsupported claim” alerts).
- Model Versioning & Impact Metrics: Track which model version was used, compare performance metrics (accuracy, trust-score) across versions.
Phase 2: Human-in-the-Loop & Governance
- Review Dashboard: A UI where domain experts can accept/reject LLM responses, annotate issues, trigger re-training.
- Feedback Loop Integration: Use expert judgements to update retrieval weights, graph edges, or even fine-tune the model.
- Policy/Guardrail Engine: Let enterprises define rules (e.g., “never output personal data”, “must cite at least 2 graph nodes”, “no legal advice without review”). Enforce those rules automatically.
- Compliance & Data Privacy Controls: Mask sensitive entities, support role-based access to graph segments, and log all user-access to knowledge graph.
Phase 3: Scaling & Commercialization
- Multi-tenant Support & Graph-Segment Isolation: Enterprises often want segregated environments, data isolation, permissioning.
- Model Agnostic Support: Support plug-in of different LLMs (OpenAI, Anthropic, local open weights) so customers choose their provider and risk profile.
- Graph-Auto-Update Pipelines: Build connectors and ETL to keep the knowledge graph refreshed from enterprise data sources (databases, documents, APIs).
- Certifications & Compliance Readiness: Target regulated industries (healthcare, finance, legal) by aligning to HIPAA, GDPR, SOC2 etc.
Built With
- react
- replit






Log in or sign up for Devpost to join the conversation.