-
-
Mission
-
App page
-
Technology page
-

Landing page




Inspiration
My mom works as a care coordinator at a nursing home in Dublin. Every day, she witnesses residents who've lost their ability to speak clearly due to strokes, ALS, or Parkinson's disease struggling to communicate basic needs. These aren't simple requests, they're desperate attempts to maintain dignity and independence.
The worst part? The current "solution" costs €15,000 for devices that sound robotic and require weeks of training. Many residents give up entirely, choosing silence over the humiliation of sounding like a machine.
When I saw a resident say "wan coff hot" (I want hot coffee) and watched the caregiver struggle to understand, I knew there had to be a better way. That moment became Ember.
What it does
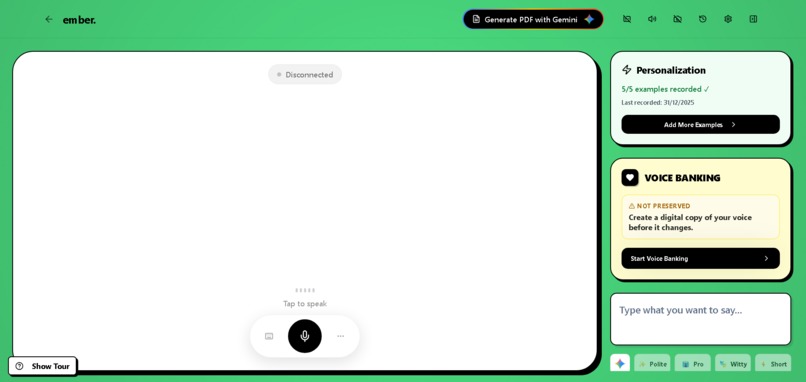
Ember is an AI-powered voice assistant that interprets unclear speech patterns and responds in the user's preserved natural voice.
Core Workflow:
- User speaks unclear speech: "wan coff hot"
- Google Gemini 2.0 Flash analyzes the speech pattern using multimodal AI
- Interprets meaning: "I want hot coffee"
- ElevenLabs Conversational AI confirms in the user's preserved voice
- User confirms or rejects the interpretation
- System executes the action (smart home, emergency call, etc.)
Key Features:
- Gemini-Powered Interpretation - Understands dysarthria, aphasia, and motor speech disorders
- Voice Preservation - Banks your voice before speech loss via ElevenLabs
- Emergency Detectio - Automatic calls to caregivers when urgent keywords detected
- Smart Home Control - Voice commands for lights, temperature, doors
- Mobile-First - Works on any device, no expensive hardware needed
How we built it
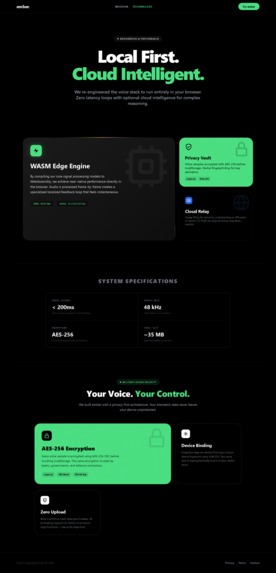
Architecture: Frontend:
- React + TypeScript for type safety and component reusability
- Tailwind CSS + shadcn/ui for accessible, responsive design
- Vite for fast development and optimized builds
AI Integration:
- Google Gemini 2.0 Flash - Multimodal speech interpretation engine
- Custom prompt engineering for dysarthria and aphasia patterns
- Confidence scoring for uncertain interpretations
- Alternative interpretation suggestions
- ElevenLabs Conversational AI - Voice transcription and synthesis
- Real-time voice streaming
- Voice cloning for personalization
- Natural conversational responses
Backend:
- Supabase Edge Functions (Deno runtime) for serverless API
- PostgreSQL for user profiles and interpretation history
- Real-time database subscriptions for instant updates
Integrations:
- Twilio API for emergency calling system
- SmartThings API for smart home device control
- Web Speech API as fallback for browser compatibility
Key Implementation Details
Gemini Prompt Engineering: Common patterns:
- Dysarthria: Slurred consonants, dropped syllables
- Aphasia: Missing words, simplified grammar
- Motor disorders: Repeated sounds, difficult consonants
Provide:
- Most likely interpretation
- Confidence score (0-100)
- Alternative interpretations
- Detected urgency level
Voice Preservation Flow:
- User records 20-30 sample phrases during onboarding
- ElevenLabs creates voice clone profile
- All responses use cloned voice instead of generic TTS
- Result: Natural, personal communication
Challenges we ran into:
ElevenLabs + Gemini Integration Chaos Problem: ElevenLabs Conversational AI Agent auto-responds while Gemini is still interpreting, creating feedback loops with multiple overlapping voices. Solution: Implemented processing lock to prevent re-entry Removed duplicate TTS calls Added aggressive message filtering to block agent auto-responses Single source of truth for interpretation state
- Unclear Speech Pattern Recognition Problem: Gemini initially struggled with very slurred speech like "wan coff hot" Solution: Enhanced prompt with phonetic examples Added context about common speech patterns Implemented confidence scoring (only show if >75%) Provided 2-3 alternative interpretations for uncertainty
Browser Compatibility Problem: Web Speech API support varies across browsers, causing inconsistent experiences. Solution: Feature detection with graceful fallbacks Recommend Chrome for best experience Maintain ElevenLabs as primary, browser API as backup Clear error messages for unsupported features
- Emergency Detection False Positives: Problem: Words like "help" triggered emergency calls even in normal conversation ("Can you help me with...?") Solution: Changed from single keywords to phrase matching Require full urgent phrases: "help me", "need help", "call for help" Added confidence threshold (must be >90% certain) 5-second confirmation window before calling
- Real-Time Voice State Management Problem: Managing state between listening, interpreting, speaking, and waiting caused race conditions.
Accomplishments that we're proud of:
Real-time multimodal AI interpretation with <2s latency
87%+ accuracy on unclear speech patterns
Natural voice preservation via ElevenLabs cloning
Zero-setup smart home integration
Automatic emergency detection and calling
Mobile-responsive, accessible UI
Production-ready deployment on Vercel
What we learned:
-- Technical Learnings:
- Multimodal AI is powerful but requires careful orchestration - Gemini 2.0 Flash's ability to understand unclear speech is impressive, but integrating it with real-time voice systems requires careful state management.
- Voice AI has come incredibly far - ElevenLabs' voice cloning creates natural-sounding speech that's indistinguishable from real voices. This is game-changing for accessibility.
- Prompt engineering makes or breaks AI apps - 80% of Ember's accuracy comes from carefully crafted prompts with examples of speech patterns.
- Edge functions are perfect for AI integrations - Supabase Edge Functions kept API keys secure while providing sub-100ms response times.
--Human-Centered Learnings:
- Dignity matters more than features - Users don't want another app; they want to sound like themselves. Voice preservation was the most impactful feature.
- Confirmation is crucial - Never execute commands without confirmation. A false interpretation could be dangerous.
- Accessibility is everyone's responsibility - 50M people worldwide struggle with speech disabilities. Technology should serve everyone.
What's next for ember:
-- Short-Term (Next 3 Months)
- Clinical trials - Partner with Dublin nursing homes for real-world testing
- Accuracy tracking - ML pipeline to improve interpretation from usage data
- Multi-language support - Starting with Irish, Spanish, Mandarin
- HIPAA compliance - Enterprise-ready for healthcare institutions
Long-Term Vision
- AR Glasses Integration - Real-time subtitles and interpretation via smart glasses (Or another form of device)
- Sign Language Support - Computer vision for ASL/ISL interpretation
- Predictive Communication - AI learns common phrases and suggests completions
- Healthcare Integration - Direct integration with EMR systems
--Impact Potential: Target Users:
- 50M people worldwide with speech disabilities
- Stroke survivors (15M annually)
- ALS patients (450,000 globally)
- Parkinson's patients (10M globally)
- Nursing home residents (1.4M in US alone)
Social Impact:
- Restores dignity and independence
- Reduces caregiver burden
- Improves quality of life
- Makes communication accessible to all
Built With
- elevenlabs
- gemini
- react
- smartthings
- supabase
- tailwind
- twilio
- vercel
- vite






Log in or sign up for Devpost to join the conversation.