-
-
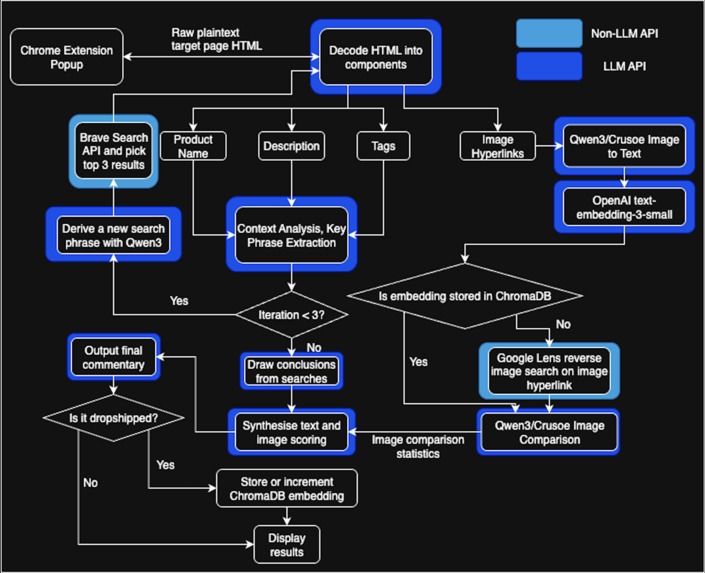
System Diagram with API Calls Highlighted
-
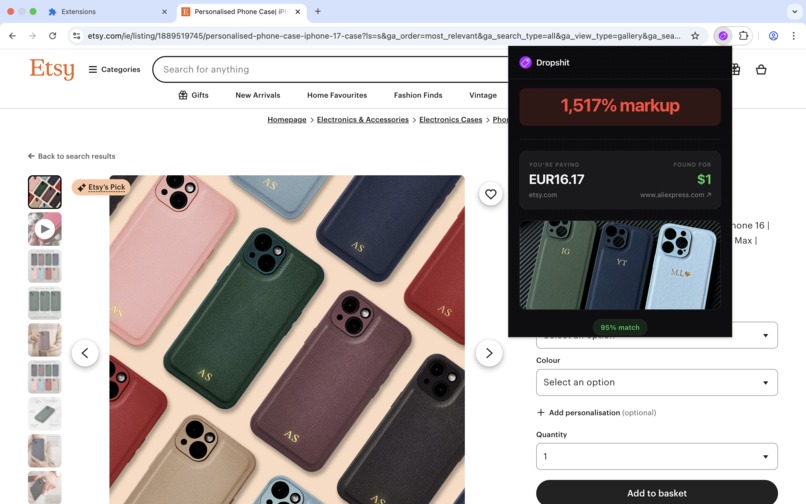
True Positive
-
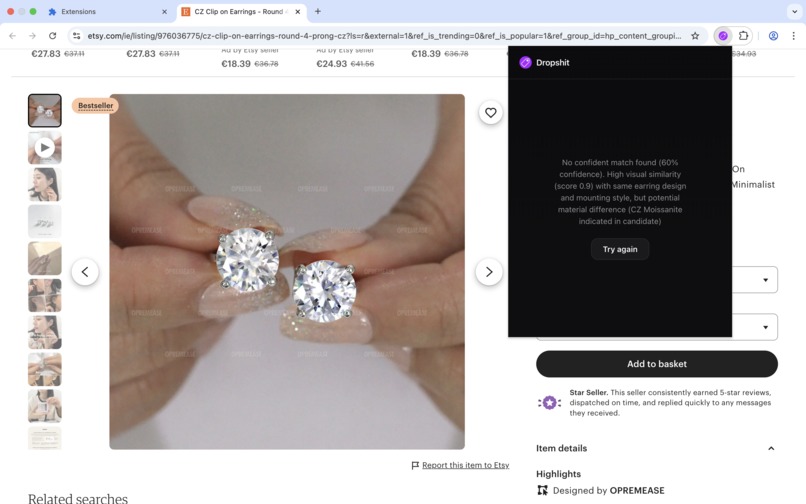
True Negative



Our Motivations for Dropshit
Shopping for products online in the year of our lord 2026 means navigating a London street full of dog poo. Dropshipping, where middle parties resell items from the original sellers for a markup, has plagued the space.
Many dropshippers employ deceptive tactics, misleading customers into believing they're spending extr on boutique art or quality craftsmanship. When the end product—often a low-quality mass-produced item resold from mass retailers—is received, it can ruin birthdays, christmasses, or the simple bliss of treating yourself to something nice.
What Dropshit Does for you
Dropshit helps you drop the shit and get right to the gold. Dropshit's system uses a mix of boutique human made tools and self-mediating agentic AI to investigate the origins of an item that you're interested in on an online shop.
Our tool will detect dropshipped listings, match against our database of most commonly dropshipped products, and help you avoid the bait. You can choose to buy the low-price, original source of the item, or to move on in your search!
How we Built it
Our frontend runs in pure JavaScript, CSS, and HTML. This is due to Google's constraints with web extensions, and meeting our goal of fast iteration.
Our backend, written in Python, delegates requests to LLMs as well as non-LLM tools to solve the problem as effectively as possible. Depending on the confidence of our models, we search between 3 and 9 online listings by reverse image search before either returning a link to a seller selling the same item for cheaper, or determining that no matches exist.
Whilst not all of our agent calls are simultaneous, we have moments of concurrency/parallelism which allow us to complete tasks faster. For extractions of key phrases from scraped textual input, inference was incredibly fast. We could compute several iterations of this in the time it took to complete image processing.
Our biggest bottleneck ended up being the reverse image search from Google Lens - we overcame this by caching results in our server through ChromaDB, a vector database for easy comparisons of LLM input encodings.
Challenges we Ran Into
We faced a lot of challenges throughout, but we 100% believe that these only improved our final product. For example, our decision to spend a lot of time on the ideation phase helped us come up with a great product rather than great technology for a product people didn't need.
3 out of the first 7 hours of the hackathon were spent tunnel-visioned on a mathematical way to reduce time spent in evals systematically, calculating correlations. Whilst this was a reasonable idea that we verified with judges, we thought it didn't have enough WOW factor. We forced ourselves onto this track, and tried too hard to make it have the WOW that Dropshit had naturally.
What we're Proud of
We created a user-friendly tool, solving a real problem that's plagued the internet for years. We take the burden off of the user to manually reverse image search and compare listings, automating the process of detecting duplicate products across sites.
Coming into the contest, we planned to focus hard on ideation, and it absolutely paid off. We're proud that we stuck to our guns and didn't start coding until we had a fleshed-out idea with WOW factor, instead of building something technically flashy that users wouldn't get any value out of.
What we Learned
We learned how to work together as a team under pressure, delegating tasks effectively in a time crunch. We learned the importance of ideation and exploring a wide range of ideas, as we spent a lot of time deep-diving into technical ideas that nobody would have used before eventually coming up with Dropshit.
What's next for Dropshit
We plan to host Dropshit on the Chrome Web Store, allowing anyone in the world to use it.
We'd like to improve our procedures to avoid anti-bot measures from dropshipping websites.
Built With
- chromadb
- chrome
- javascript




Log in or sign up for Devpost to join the conversation.