-
-
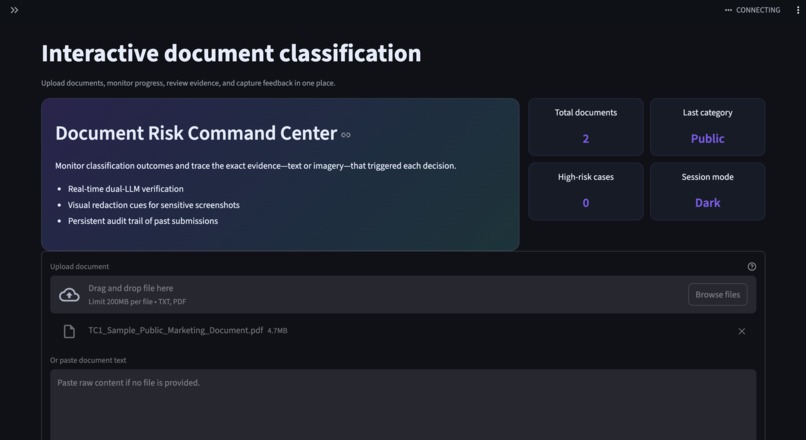
landing page

Inspiration
We often spend too much time fixing small issues in reports and submissions rather than focusing on the ideas. As graduate students we juggle courses research and teaching so we wanted a reliable assistant that catches mistakes early makes expectations transparent and frees us to focus on substance. We also see peers struggle with formatting rules citation consistency and missing sections which creates avoidable delays in reviews and collaborations.
What it does
DocChecker reviews a document and gives precise feedback on structure style citations figures tables and compliance with a chosen template or guideline. It flags missing sections broken references inconsistent terminology and readability problems. It can check citation formats and reference integrity extract key metadata and produce a short summary of strengths and issues. A dashboard shows overall readiness and a prioritized list of fixes with suggested edits.
How we built it
We built a modular pipeline with separate stages for parsing analysis and feedback. Parsing supports common formats like PDF Word and Markdown using robust text extraction and layout heuristics. Analysis combines rule based checks with natural language techniques for section detection terminology consistency and readability scoring. Feedback is generated through a small service that ranks findings by impact and suggests edits with examples. The backend uses Python with FastAPI and a small queue for longer jobs. We store document metadata and findings in a relational database. The interface is a simple web client that allows drag and drop upload template selection and side by side diff of suggested edits.
Challenges we ran into Reliable text extraction from complex PDFs was difficult especially with multi column layouts and math. Balancing strictness with usefulness required iteration since overflagging reduces trust while underflagging misses important problems. Template variability across venues and advisors made generalization a challenge. We also needed to design explanations that are short clear and actionable so that users can fix issues quickly without reading a long report.
Accomplishments that we're proud of
We reached strong section detection accuracy across diverse research papers and proposals. Our citation integrity check finds broken references and unmatched entries with high recall. The interface shows clear suggestions aligned to the original text which reduces friction during revision. Early users reported that DocChecker cut their final proofreading time by a large margin while improving consistency.
What we learned
High quality feedback depends as much on explanation design as on model accuracy. Investing in robust parsing pays off more than clever ranking when documents are messy. Users prefer a small set of important recommendations over a long list of minor issues. Finally templates must be transparent and editable so teams can adapt rules to local expectations.
What's next for DocChecker
We plan to add collaboration features so advisors and coauthors can leave structured checks and approve fixes. We will expand template libraries for common conferences theses and grant calls and allow custom templates with a visual editor. We are exploring detection of ambiguous claims unsupported figures and data availability statements. We also want a lightweight plugin for common editors that gives guidance as you write to prevent issues before they appear.
Built With
- fastapi
- ollama
- pdfplumber
- python
- sqlalchemy-(sqlite)
- streamlit



Log in or sign up for Devpost to join the conversation.