-
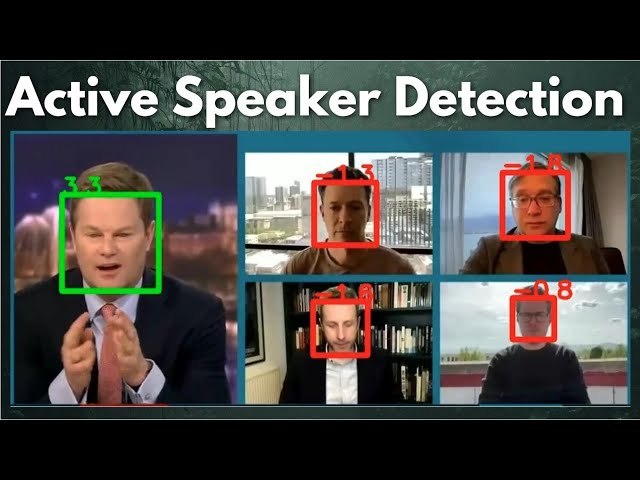
ASD within a video conference

Inspiration:
The idea for this project stemmed from the increasing reliance on video conferencing, live streaming, and automated transcription services. With the rise of remote work and virtual meetings, the need for accurate speaker detection has never been greater. I wanted to explore how machine learning and computer vision could be leveraged to make real-time communication more efficient and accessible.
What it does:
This project utilizes computer vision and multimodal computing techniques to detect the active speaker in a video. By analyzing both visual and audio cues, the system can accurately determine who is speaking at any given moment. The output can be used for various applications, such as automatic transcription, speaker tracking, and real-time video conferencing enhancements.
How I built it:
The project was built using:
- OpenCV for face detection and tracking.
- ResNet-based models for visual feature extraction.
- Audio processing techniques to correlate speech with detected faces.
- Python and Flask for backend processing.
- JavaScript and HTML/CSS for the front-end visualization and user interface.
The system integrates both visual and auditory features, ensuring high accuracy in detecting the active speaker. By combining deep learning with traditional signal processing, it achieves real-time performance without requiring excessive computational resources.
Challenges I ran into:
Building a robust active speaker detection system came with several challenges:
- Synchronizing audio and video data was complex, as minor desynchronizations could lead to incorrect speaker attributions.
- Handling multiple speakers in a frame required efficient association techniques to match faces with corresponding voices.
- Optimizing real-time performance while maintaining accuracy was crucial for making the system practical.
- Overcoming background noise and overlapping speech to prevent misclassification.
Accomplishments that I'm proud of:
- Successfully implemented a real-time speaker detection system.
- Achieved reliable accuracy in various lighting and noise conditions.
- Developed an intuitive UI to visualize speaker identification results.
- Optimized the model for smooth execution on consumer-grade hardware.
- Created a modular, scalable codebase that can be expanded for further improvements.
What I learned:
This project provided invaluable insights into:
- The importance of synchronizing multimodal data streams.
- The trade-offs between computational efficiency and model accuracy.
- Best practices for deploying real-time machine learning applications.
- The potential of deep learning in audio-visual fusion tasks.
What's next for CVMC:
Looking forward, several improvements and extensions can be made:
- Enhancing model accuracy by integrating more advanced neural architectures.
- Support for multiple simultaneous speakers with better voice assignment algorithms.
- Integration with live streaming platforms for real-time speaker identification.
- Expanding accessibility features, such as automatic subtitle generation and translation.
- Deploying a web-based demo to allow users to test the system online.
By continuing to refine and expand the project, CVMC can play a crucial role in making video-based communication smarter and more intuitive.
Log in or sign up for Devpost to join the conversation.