-
-
Login screen
-
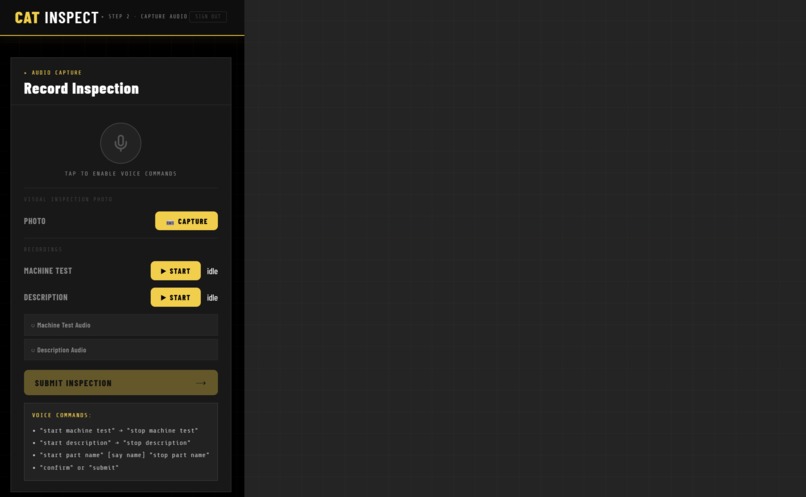
Recording screen


CATalyze — AI-Powered Field Inspection
Inspiration
Every day, CAT equipment operators conduct walkaround inspections the same way they've done it for decades: clipboard in hand, eyes on the machine, mental notes flying. The findings get written up later, if they get written up at all. CAT has built two powerful tools to modernize this: CAT Inspect for structured reporting, and CAT AI Assistant for intelligent, conversational guidance. But they've never been unified.
That gap was our inspiration. What if a single app could let an operator conduct a full inspection hands-free — speaking naturally, recording machine sounds, snapping a photo — and receive a professional-grade, standards-aligned PDF report automatically, with no forms and no paperwork? What if the AI could catch a mechanical fault the operator didn't notice, or flag when instrument readings contradict what the operator is verbally reporting? That's CATalyze: the convergence of CAT Inspect and CAT AI Assistant into something neither tool could be alone.
What We Built
CATalyze is a voice-first, multimodal inspection assistant. An operator opens the app, speaks a part name, records a short machine audio sample, describes what they observe verbally, and snaps a photo — all without touching a screen. Three independent AI signals are captured:
- Whisper large-v3 transcribes the spoken description in real time
- Fine-tuned Wav2Vec2-Large analyzes the machine audio for acoustic fault signatures (imbalance, obstruction, bearing wear)
- Fine-tuned EfficientNet-B0 classifies the photo for visual defects
All three signals are then passed to Phi-3.5-mini-instruct, which reasons across them to produce a structured inspection report: an overall risk rating (HIGH / MEDIUM / LOW), a 2–3 sentence executive summary, prioritized immediate action items, and a per-component breakdown with urgency classifications and corrective actions. The output is rendered as a PDF that mirrors the CAT Inspect standard report format — ready to share, file, or act on immediately.
A critical design decision: when sensor data contradicts the operator's verbal report — say, the AI detects 100% confidence fan imbalance while the operator says "everything sounds fine" — CATalyze trusts the instruments and escalates the risk rating. This mimics how a trained CAT technician would reason through conflicting signals, and it's the kind of judgment that prevents equipment failures before they become safety incidents.
How We Built It
The frontend is built in React 19 with TypeScript, deployed on Cloudflare Pages. A lightweight local login captures the operator's name and ID for the report. The recording screen uses react-speech-recognition for continuous voice command detection alongside the native MediaRecorder API for machine audio capture — two recording streams that had to be carefully coordinated so they didn't interfere with each other.
The backend runs entirely on Modal serverless GPU containers — four independent endpoints, each on its own hardware tier:
- Whisper transcription on T4
- Wav2Vec2 acoustic anomaly detection on T4 (fine-tuned on CAT equipment fault patterns)
- EfficientNet visual anomaly detection on T4 (fine-tuned on equipment imagery)
- Phi-3.5-mini-instruct LLM reasoning + PDF generation on A10G
Both the acoustic and visual models were trained from HuggingFace pre-trained checkpoints on Modal A100 compute, with classification heads fine-tuned on labeled fault data. The models are stored in Modal Volumes and loaded lazily, keeping cold-start times under 5 seconds.
The LLM prompt is a carefully engineered multi-shot system with chain-of-thought reasoning that forces the model to output a strict JSON schema — with explicit rules for when to escalate risk, how to handle conflicting signals, and what corrective actions to recommend per fault type. Post-processing validates and extracts the JSON before PDF rendering with fpdf2.
Challenges We Faced
Forcing LLM output into a strict schema, consistently. The inspection report PDF depends on a precise JSON structure — overall_risk_rating, executive_summary, immediate_actions, and per-part urgency and recommended_action fields. Getting Phi-3.5-mini to respect this schema every time, without hallucinating keys or wrapping output in markdown, required carefully designed multi-shot prompts with grounded reasoning examples covering each edge case: sensor-only anomalies, operator-only anomalies, and the critical contradiction case where verbal report and sensor data conflict. The chain-of-thought "let's think step by step" structure helped significantly.
Coordinating two simultaneous recording streams. The voice command system (SpeechRecognition API) and the machine audio recorder (MediaRecorder API) both need the microphone at the same time, but they fight each other. We had to pause SpeechRecognition before starting the native MediaRecorder for the acoustic sample, then resume it afterward — and do this in a way that felt seamless to the operator with no perceptible gap in voice command detection.
Baking local files into Modal containers. Modal builds container images at deploy time, not at request time. Our prompt template lives in prompt.txt on disk, but the inference container can't access the local filesystem at runtime. We had to explicitly mount local files into the container image using add_local_file during the build step — a non-obvious Modal pattern that took some debugging to get right.
What We Learned
The most important lesson: AI is most powerful when it's invisible. The best moments in CATalyze are when the operator just talks and walks, and a professional report appears — no menus navigated, no forms filled. Getting there required hiding a lot of complexity: coordinating three AI models, handling their outputs consistently, and presenting only the result. Every piece of friction we removed from the inspector's workflow required adding engineering discipline somewhere else.
We also learned that prompt engineering is a first-class engineering discipline, not a shortcut. Getting an LLM to consistently produce a schema that a PDF renderer can rely on — especially one that makes correct judgment calls about conflicting data sources — requires the same rigor as writing deterministic code. The examples, the ordering of guidelines, the chain-of-thought instruction all matter in ways that aren't obvious until something breaks at 2am.
Log in or sign up for Devpost to join the conversation.