-
-

Thumbnail
-
-
-
-
-
-
-

-
-










Inspiration
Deep Research agents are extremely promising. aspects of LLMs, but they have some key issues. 1 A basic LLM can tell you something, but it is not verifiable. It has fuzzy knowledge of the entire internet, but you cannot ask it how it knows what it knows. Worse, LLMs tend to be confidently incorrect. For fields like medicine, law, or trading, this is unacceptable. 2 Any agent that uses the internet quickly runs into the context problem. A single site can easily exceed 500k tokens of information. Current implementations either read the first ~10k tokens of many sites or read fully only one or two. We beat this context window with our project: BeeWork. Imagine if you could had AI agent with more knowledge than a domain expert?
What it does
For an Agent to be a domain expert, it needs a source of concise, structured, and cited information. We call that a knowledgebase.
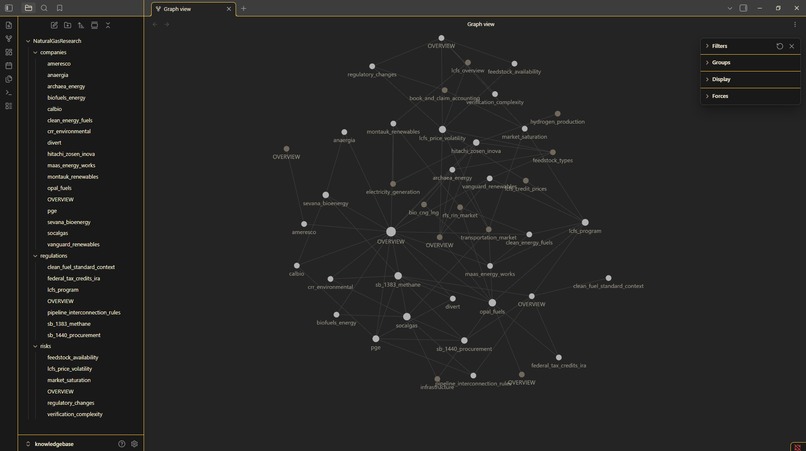
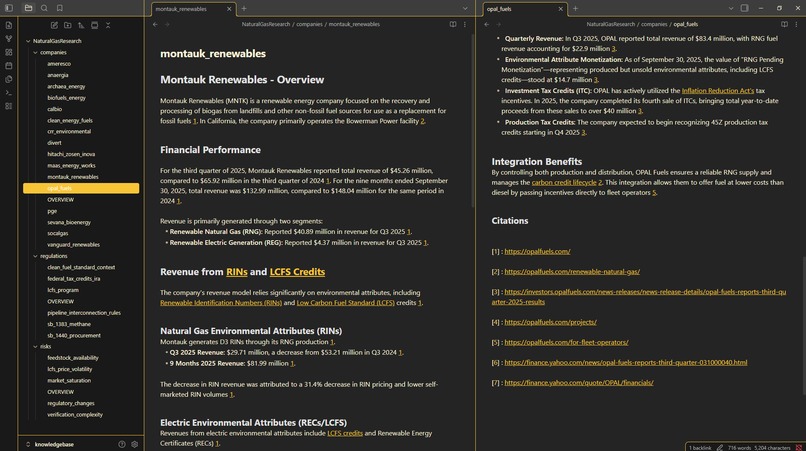
A knowledge base is like a wiki, it has citations to primary sources and links to other pages within the wiki. An agent can search with grep, navigate to linked pages, and visit primary sources to verify information. The best LLM is one with the best context.
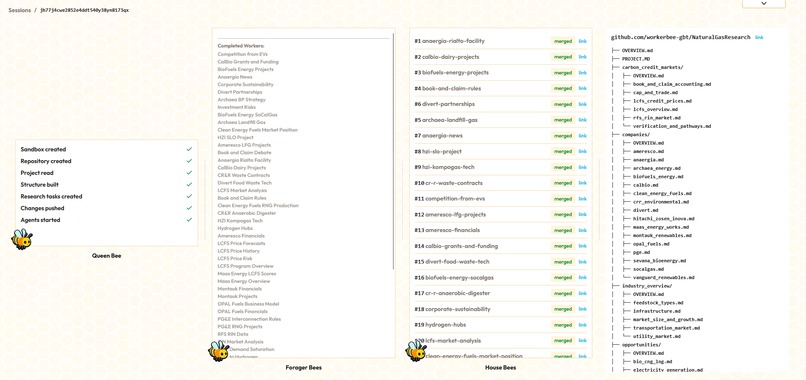
Our knowledge base is a filesystem of .md files hosted on GitHub. Agents like filesystems, they understand them natively. We also host our knowledgebase on GitHub. Agents also like git, they can use git commands flawlessly, know how to deal with merge conflicts, and GitHub records all changes and attributions.
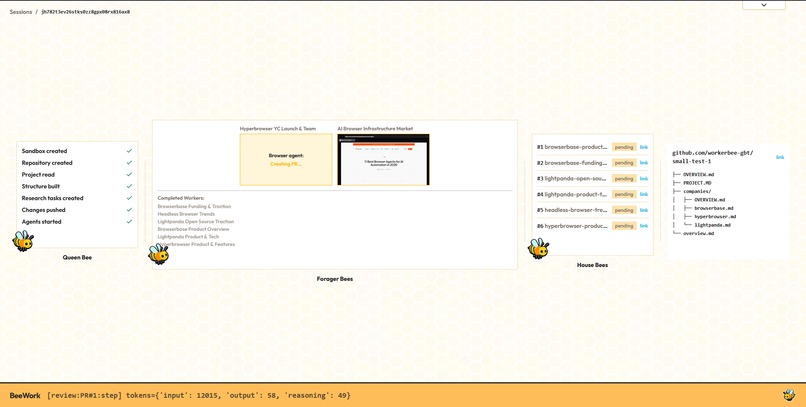
Here is how BeeWork uses many agents working together to create a knowledgebase.
1. Project requirements
We start with a handwritten file called PROJECT.md of what the knowledgebase needs to be about
2. Orchestrator (Queen Bee Agent)
The orchestrator reads PROJECT.md searches the web with Parallel, reading shallowly (just 2000 tokens) from many sites over many search queries. This gives it a broad understanding, which it uses to define the folders of the repo, like companies/, risks/ or regulations/. Then it creates a list of several questions for each site that appeared in searches, like "Look on https://www.waterworld.com/ for information on the economic feasibility of WWTP biogas upgrading."
3. Researcher (Worker Bee)
Each one of these >100 research questions gets sent to a Browser Use agent that visits the page like a real person, interacting and searching for the target information. Every page that it visits along the way is recorded for attribution. The results are written as a file along with citations. Then the agent clones the knowledgebase, reads existing relevant files, and edits them to add in new information. This is submitted as a pull request.
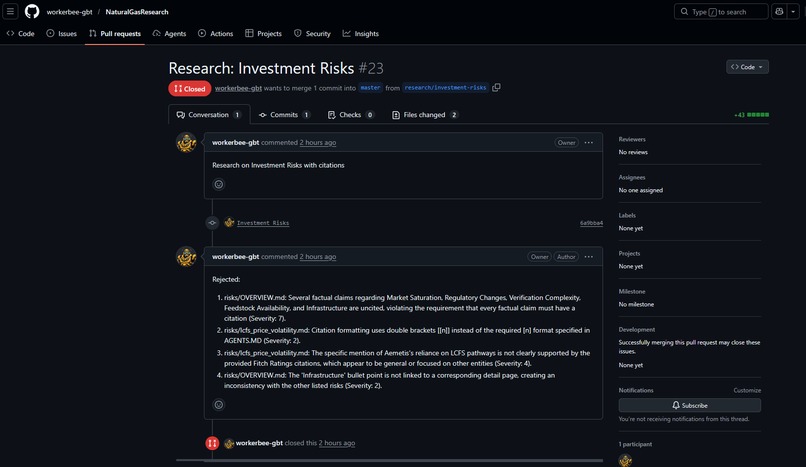
4. Reviewer (House Bee)
Every pull request is reviewed by another agent. This agent serves to validate the added information, check for formatting mistakes, missing or invalid citations, and evaluate the overall quality and novelty of the contribution. Because this agent does not have the context and goal pollution of the raw website data, it improves the quality of the pull requests with edits and rejects ones that do not meet our standards. It also handles merge conflicts.
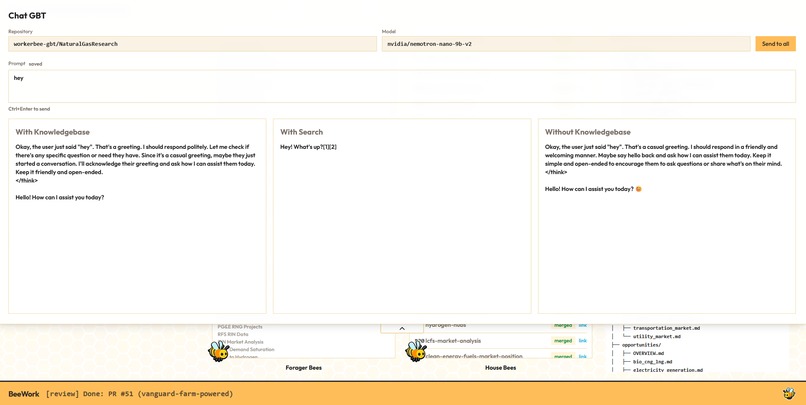
AI Consultant (Chat GBeeT)
Finally, we have a single agent with access to the knowledgebase who can answer questions about this domain with expert and cited responses. While this chat agent is the actually useful part for end consumers, our innovation lies in the agents that work together to create and maintain the knowledgebase this chat agent relies on.
How we built it
Every agent is a OpenCode agent running in a Modal sandbox.
Coding agents are really good. In fact, we believe they are better than plain tool calling agents even at calling tools.
So every "tool" we make for our agent is actually just a python script, that the coding agent can read, run, or edit with its coding and terminal primitives. This completely unbinds the agent to adapt to and fix unexpected conditions. And the sandbox takes care of any safety concerns.
We tuned each of our agents using Laminar, a fullstack observability tool for Agents. It shows us every command and message our agents run, and enables us to make tweaks to the system prompts to make each one more efficient and effective.
The browser agents are run on Browser Use cloud, which has effective and fast actions, and handles stealth and authentication very well, allowing us to visit sites that other browser agents get blocked at.
We also made a frontend observability tool and made it bee themed. It showcases the status of each knowledgebase, browser agent, reviewer, and has a chat interface where the AI Consultant with knowledgebase, plain LLM, and LLM with search respond in parallel for comparison.
To view the actual knowledgebases themselves, we use Obsidian, a great application for viewing linked markdown files. We especially like the graph view.
We considered using the Claude Code agent SDK for the prize, but we prefer open source so used OpenCode. For LLMs, we found Claude Opus 4.6 works best for orchestrator and reviewer, and Gemini 3 flash was best for the workers. But we ran out of anthropic credits quickly so we used Gemini for everything.
For coding we made a monorepo with one folder per agent with sandbox config, the system prompt and the useful tools as python files. The agent is given its folder in a sandbox and told "Read AGENTS.md and use tools in tools/ to complete your task." This was a very generalizable and effective agent framework.
Alex used Cursor and Kumar used Antigravity, both with Claude Opus 4.6. We read every line of code to ensure quality, total spend was about $50. In the 36 hours for the hackathon, we worked for 28.5.
Challenges we ran into
Combining the deep results of many browser agents into a structure that is more accurate and more concise than the sum of its parts is the main challenge we faced. Adding and tuning the reviewer agents as adversaries to the workers is what really solved this for us, and when we started to be amazed by the knowledgebases produced.
The challenge that we did not expect is that once we started testing >50 concurrent agents all pushing to the same github from different sandboxes, our google and github account for our agent were abruptly terminated for suspicious behavior and the accounts and all data were deleted. We lost all of our knowledgebases, 30 mins before the deadline. We made another account and rebuilt, but it also got deleted midway during judging.
Moving forward, we will have to get an enterprise GitHub account for the bot, or host git on our own server.
Accomplishments that we're proud of
We are really proud of the quality of knowledgebases produced. In our demo video, we create a very small knowledgebase about Alzheimer's, and ask the AI Consultant a question from a premed friend. The Agent with our knowledgebase had a more accurate answer than plain LLM and a search Agent. Furthermore, since our agent cited the original source we got to visit the original paper and verify the finding. When we did, we realized that the plain and search LLM were reporting the result in the paper's abstract (a shallow read into the page) but our agent had the additional information only found later in the paper. We really believe that knowledgebases are the future of AI intelligence in areas where you cannot afford to have any inaccurate information.
We have a larger knowledgebase (recovered partially after GitHub deleted our bot) about renewable gas in California that you can view yourself here: https://github.com/Alezander9/RenewableGasCalifornia
What's next for BeeWork
stanford roomates -> lovers -> cofounders
Built With
- anthropic
- browser-use
- claude
- cloudflare
- gemini
- laminar
- modal
- nemotron
- nvidia
- openai
- opencode
- parallel
- python
- vercel


Log in or sign up for Devpost to join the conversation.