-
-
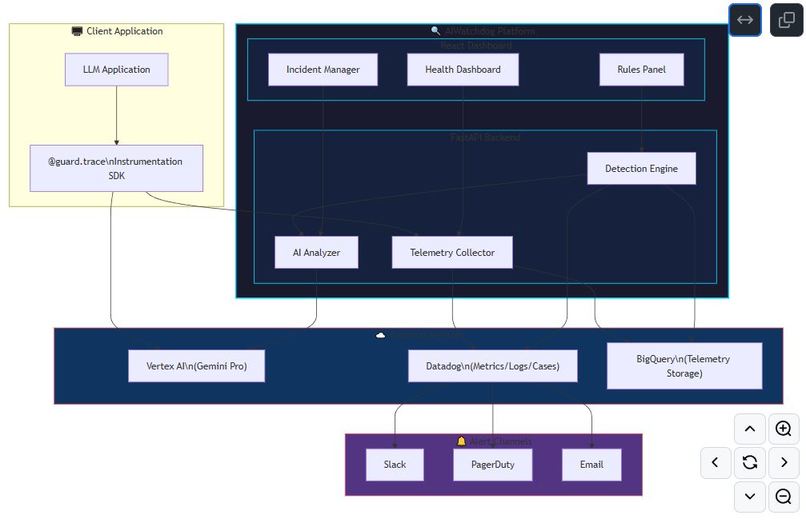
system architecture

Inspiration
I noticed a critical gap in the Generative AI stack: Observability is currently passive. Developers deploy LLM applications, but when they fail (hallucinations, latency spikes, high costs), tools just show a red graph. We wanted to build an "immune system" for AI applications—a platform that not only detects pathogens (bad prompts, errors) but actively analyzes them and suggests cures.
I were inspired by the idea: What if the same AI that powers your app could also debug it?
What it does
AIWatchdog is a comprehensive observability suite designed specifically for Google Vertex AI and Datadog users.
- Zero-Touch Instrumentation: With a single line of code (
@guard.trace), it hooks into Python functions to capture latency, token usage, cost, and full prompt/completion text. - Smart Detection Engine: It monitors streams of data for specific semantic triggers—like Prompt Injection attacks, Hallucination rates, or Cost Anomalies.
- AI-Powered Root Cause Analysis: When an incident occurs, AIWatchdog feeds the failure context back into Gemini 1.5 Flash. The model analyzes the stack trace and inputs to determine why it failed (e.g., "The prompt was ambiguous," or "Downstream rate limit").
- Actionable Alerts: It pushes rich, context-aware incidents to Datadog, complete with the AI's recommended fix, turning a generic "Error 500" into a solved ticket.
How we built it
I architected AIWatchdog as a bridge between the raw execution layer and the operations layer.
- The SDK: I built a lightweight Python SDK that uses
asyncioto send telemetry without blocking the main application thread. It parses Vertex AI responses to extract token counts relative to the specific model (Gemini 1.5 Flash/Pro). - The Backend: Built with FastAPI, it serves as the aggregation hub. It holds the "Detection Rules Engine" which evaluates incoming traces against user-defined logic (e.g.,
latency > 5s AND status = 'error'). - The "Judge": I integrated Vertex AI (Gemini) as a sophisticated backend service. Instead of generating content for users, this instance is prompted to act as a Reliability Engineer, reviewing logs and suggesting optimizations.
- The Frontend: A responsive, data-heavy dashboard built with React, Vite, and Recharts. I used Tailwind CSS with a glassmorphism aesthetic to make the data visualization pop.
Challenges we ran into
- Latency vs. Observability: Early versions of our SDK added ~500ms of latency to every call because we were sending HTTP requests synchronously. Refactoring to an asynchronous, non-blocking fire-and-forget pattern was essential.
- Handling Non-Determinism: Unlike traditional software, LLMs don't always fail the same way twice. Writing detection rules for "Hallucinations" required creativity—we implemented a "Confidence Score" heuristic to flag potential issues.
- The "Refactor": Mid-hackathon, we decided to rebrand from specific nomenclature to the broader "AIWatchdog". Renaming the core SDK classes and files across the entire stack while keeping the git history clean and the build green was a high-pressure DevOps challenge.
Accomplishments that we're proud of
- True "Self-Healing" Workflow: We successfully demonstrated a loop where an injected error creates a Datadog incident containing a human-readable fix generated by AI.
- Developer Experience: The Setup Wizard takes less than 60 seconds to configure. We're proud of how polished the onboarding flow feels.
- Enterprise-Grade Integration: We didn't just mock the data; we built a real Datadog API Client that pushes custom metrics and events, making this a viable tool for real-world teams.
What we learned
- LLMs are excellent debuggers: I was surprised by how accurate Gemini 1.5 is at diagnosing unexpected software behavior when given the right log context.
- Metadata is everything: A raw error log is useless. A log attached to the specific prompt, model version, and cost of the query is gold.
- The "Observer Effect": You have to be extremely careful when measuring AI performance not to impact it. Minimizing overhead was our top technical constraint.
What's next for AIWatchdog
- Active Interception: Instead of just alerting, we want to implement a proxy layer that can block malicious prompts (like injections) before they even hit the expensive LLM.
- Autotuning: Using the cost metrics to automatically suggest when to downgrade a prompt from Gemini 1.5 Pro to Flash to save money without losing quality.
- Multi-Modal Support: Extending our tracing to cover image and video generation inputs/outputs.
Built With
- datadog
- fastapi
- gcp
- gemini
- javascript
- python
- react
- recharts
- vertexai
Log in or sign up for Devpost to join the conversation.