-
-
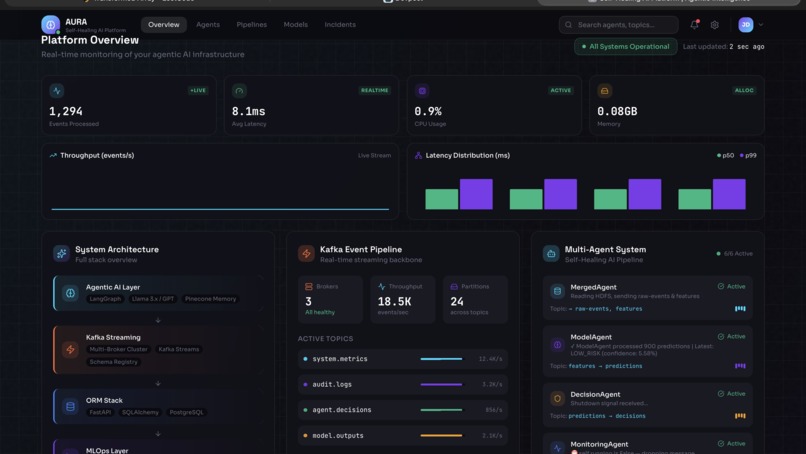
UI

Inspiration
Traditional IT operations teams spend countless hours firefighting production incidents manually monitoring systems, diagnosing issues, and implementing fixes while downtime costs businesses thousands per minute. We envisioned a future where infrastructure could be self-aware and self-healing, where AI agents work together like an immune system to detect, diagnose, and resolve issues autonomously before they escalate into outages.
What it does
Our Agentic Self-Healing Platform is an intelligent multi-agent system that autonomously monitors, analyzes, and repairs production infrastructure in real-time. The platform consists of six specialized AI agents working in concert:
- MergedAgent ingests raw events and feature data from HDFS
- ModelAgent analyzes patterns and generates risk predictions using ML models
- DecisionAgent evaluates predictions and makes automated decisions
- MonitoringAgent continuously watches system metrics and triggers alerts
- HealingAgent executes remediation actions when incidents are detected
- AGL manages policy approvals and governance workflows
These agents communicate through Kafka message streams, creating a reactive pipeline that can detect anomalies, make intelligent decisions, and execute healing actions, all without human intervention. The system features a real-time dashboard that visualizes agent activity, system metrics, and the flow of data through the pipeline.
How we built it
Backend Architecture:
Built a distributed multi-agent system in Python with each agent as an independent microservice Implemented Apache Kafka for event streaming and inter-agent communication Integrated machine learning models for anomaly detection and risk prediction Added a fallback rule-based system for safe-mode operation when ML models are unavailable Stored logs and metrics in a structured file system for auditing and analysis
Frontend Dashboard:
Developed a Next.js web application with real-time updates using Server-Sent Events (SSE) Created interactive visualizations with Framer Motion for agent status and system health Implemented Kafka consumers in Node.js to stream logs and metrics to the browser Designed a responsive UI that displays the complete data pipeline flow
Integration Layer:
Connected Python backend agents to Next.js frontend via Kafka topics Set up API routes for log file analysis and event counting Implemented real-time synchronization between agent states and UI displays
Challenges we ran into
Kafka Message Flow Issues: The most significant challenge was achieving reliable message flow through Kafka. Initially, our topics weren't receiving messages due to mismatched data structures between producers and consumers. We spent considerable time debugging schema inconsistencies, where one agent would produce a message format that another agent couldn't parse. Additionally, we encountered issues where consumers were subscribed to incorrect topic names or multiple consumers were competing for the same messages, leading to missed events.
Backend-Frontend Integration: Connecting the UI with backend logs proved extremely challenging. We initially tried several approaches direct file reading, REST polling, WebSockets before settling on Server-Sent Events. The complexity increased when trying to count events from log files in real-time, as we had to handle file I/O in Next.js Edge runtime (which doesn't support Node.js modules), manage log file naming conventions across agents, and create efficient regex patterns to parse diverse log formats without degrading performance.
LLM Latency and Accuracy: Our initial architecture relied on a large reasoning LLM to make all decisions, but this created a bottleneck. The LLM responses were slow (3-5 seconds per decision) and sometimes produced inconsistent or inaccurate recommendations for system healing actions. This taught us that monolithic AI decision-making doesn't scale for real-time operations.
State Management Complexity: Coordinating state across six independent agents while maintaining consistency was non-trivial. We had to implement careful error handling to prevent cascade failures where one agent's crash could bring down the entire system.
Accomplishments that we're proud of
Built a fully functional multi-agent system that can autonomously detect and respond to system issues in real-time
Achieved sub-second latency in the complete pipeline from anomaly detection to healing action execution
Created a production-grade architecture with proper separation of concerns, fault tolerance, and graceful degradation
Designed an intuitive real-time dashboard that makes complex distributed systems observable and understandable
Implemented a working Kafka-based event streaming pipeline that handles thousands of events per second
Solved the distributed coordination problem by having agents communicate through message passing rather than shared state
What we learned
Multi-Agent Systems > Monolithic LLMs: Rather than deploying a single reasoning LLM, we discovered that a more time-efficient and reliable architecture emerges from using specialized agents that each handle a specific decision in the chain. This agent-based approach provides:
Faster decisions: Each agent is optimized for its specific task, eliminating the overhead of a general purpose LLM Better reliability: If one agent fails, others continue operating; the system degrades gracefully Easier debugging: Problems can be isolated to specific agents rather than a black-box LLM Cost efficiency: Lightweight models and rule-based agents are cheaper to run than continuously querying large LLMs
Event-Driven Architecture is Essential: Using Kafka for agent communication taught us the power of event-driven systems. Decoupling agents through message streams made our system more resilient, scalable, and easier to extend with new capabilities.
Real-Time Observability Matters: Building the dashboard taught us that invisible automation is useless in production. Operators need to see what's happening, even if they're not taking action. The real-time visualization helped us debug issues and build trust in the autonomous system.
What's next for Agentic Self Healing Platform
Integrate more sophisticated ML models for predictive maintenance by fixing issues before they occur Add reinforcement learning so agents improve their healing strategies over time based on outcomes Implement cross-agent learning where successful patterns from one deployment help others. Build a plugin architecture so users can add custom agents for domain-specific healing actions
Built With
- agent
- ai
- bash
- bun
- docker
- hadoop
- kafka
- mlflow
- mlops
- node.js
- postgresql
- prometheus-image-archive
- python
- sqlalchemy
- typescript
- zookeeper

Log in or sign up for Devpost to join the conversation.