-
-

Landing page
-

Example render
-
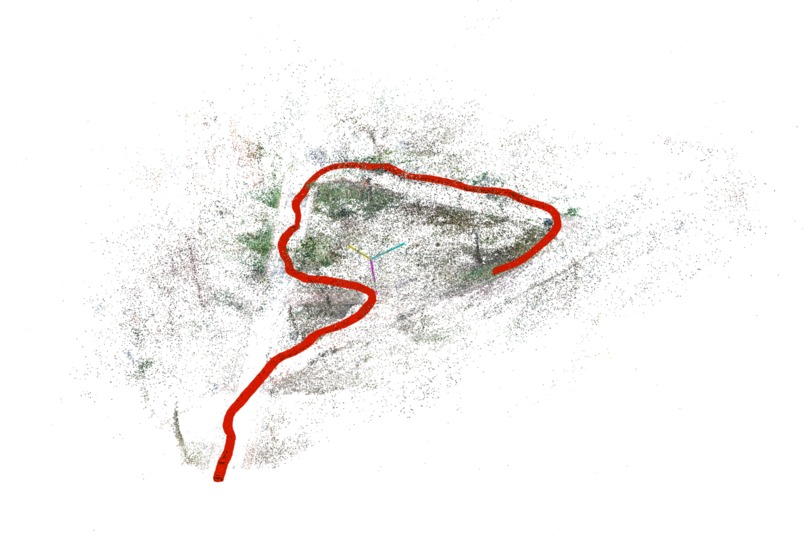
Camera trajectory
-
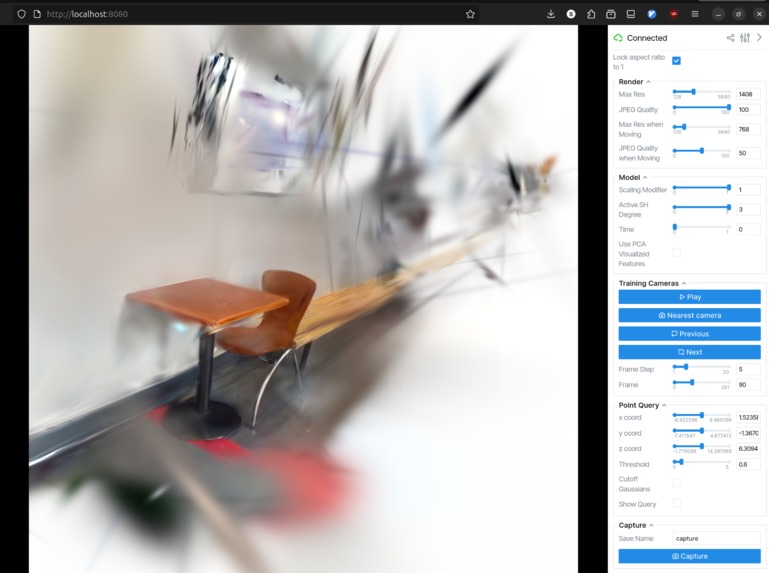
Scene editing
-

Training with render and uncertainty map
-

Segmentation of object in the image






4D2³ - Video to Cubed: 3D Gaussian Splatting with Scene Editing
Inspiration
As undergraduate researchers in computer vision, we were inspired by the challenge of transforming ordinary video footage into immersive, interactive 3D experiences that not only capture the geometry but also understand the semantic content of scenes. The goal was to bridge the gap between 2D video content and truly intelligent 3D representations that can be edited, manipulated, and understood at a semantic level.
Our inspiration came from the practical need to for 3D scene understanding for applications ranging from virtual reality content creation to touring a campus or finding an apartment. We wanted to create a system that could take any video (4D) and transform it into a 3D (2^3) experience with intelligent object recognition and interactive editing capabilities. That way, end users can interact with a digital twin in place of the real world, allowing experimentation and exploration.
What it does
4D2³ (Video to Cubed) is an 3D Gaussian Splatting system that transforms 2D video sequences into interactive, semantically-aware 3D scenes. The system builds on top of a state-of-the-art computer vision method, EgoLifter, to create immersive 3D experiences with editing capability.
Key Features:
- 3D Reconstruction: Converts video footage into 3D Gaussian splats using COLMAP-based structure-from-motion
- Semantic Scene Understanding: Integrates Segment Anything Model (SAM) for automatic object detection and segmentation
- Interactive 3D Editing: Provides GUI tools for object selection, deletion, and manipulation in 3D space
- Multi-Scene Visualization: Supports simultaneous viewing of multiple 3D scenes with independent viewers
- Real-time Rendering: Delivers an interactive 3D experiences with modern WebGL-based visualization using Viser.
How we built it
The 4D2³ system is built on a pipeline from EgoLifter combining multiple technologies:
Core Architecture:
- 3D Gaussian Splatting: Implemented using gsplat library for efficient 3D point cloud representation
- COLMAP Integration: Automated camera pose estimation and sparse 3D reconstruction
- SAM Integration: Segment Anything Model for semantic object detection and segmentation
- PyTorch Lightning: Scalable training framework with distributed computing support
- Viser Viewer: Modern WebGL-based 3D visualization with interactive controls
Technical Stack:
- Backend: Python, PyTorch, CUDA for GPU acceleration
- 3D Processing: COLMAP, gsplat, custom Gaussian manipulation algorithms
- Computer Vision: SAM, GroundingDINO, CLIP for semantic understanding
- Frontend: HTML5, CSS3, JavaScript with WebGL rendering
- Infrastructure: Multi-process architecture supporting concurrent viewers
Development Process:
- Data Pipeline: Automated COLMAP processing for camera pose estimation
- SAM Integration: Real-time object detection and segmentation across video frames
- 3D Training: Custom Gaussian splatting with contrastive learning objectives
- Interactive Interface: Web-based 3D viewer with intuitive editing controls
- Multi-Viewer System: Concurrent visualization of multiple scenes
Key Technical Innovations:
- Custom buffer management for PyTorch registered tensors
- Modified the pipeline to utilize a smaller SAM model, allowing the pipeline to run on a laptop
- Multi-port viewer architecture for independent scene visualization
- Dynamic HTML generation for flexible user interfaces
Challenges we ran into
Technical Challenges:
CUDA Compilation Issues: Encountered complex CUDA environment conflicts requiring custom workarounds and environment variable management for proper gsplat compilation.
PyTorch Buffer Management: Faced critical IndexError issues with registered PyTorch buffers during Gaussian model initialization
WebGL Context Conflicts: Struggled with browser limitations when embedding multiple 3D viewers in iframes, leading to WebGL context conflicts and performance degradation.
SAM Integration Complexity: Required extensive environment setup with multiple dependencies (GroundingDINO, SAM, Tag2Text) and careful path management for detection file generation.
Accomplishments that we're proud of
Technical Achievements:
Successful Multi-Scene Training: Successfully trained models on diverse scenes including indoor objects (chair), outdoor campus environments (Penn), and complex urban settings (Drexel) with a combined 1500+ camera viewpoints.
Buffer Management: Solved PyTorch buffer initialization issues with drop in fixes for proper tensor resizing.
Multi-Viewer Architecture: Created a multi-process system supporting three independent 3D viewers with automatic process management and clean shutdown procedures.
UI/UX: Designed a landing page with descriptive GIFs layout and custom addition to the Viser GUI
What we learned
Technical Insights:
CUDA Environment Complexity: Learned intricate details of CUDA compilation, environment variables, and cross-platform compatibility challenges.
Multi-Process Architecture: Developed expertise in Python process management, inter-process communication, and resource coordination.
What's next for 4D2³
Enhanced Editing Tools: Develop more sophisticated 3D editing capabilities including per-object transformation, scaling, and advanced selection tools.
Mobile Support: Optimize the system for mobile devices with WebGL compatibility and touch-based interaction.


Log in or sign up for Devpost to join the conversation.