-
-

Logo
-

Webpage Screenshot 1
-
Webpage Screenshot 2
-
Webpage Screenshot 3
-
Webpage Screenshot 4





Inspiration
As enthusiastic computer science students, we sought to apply our machine learning capabilities with real-world datasets in a rather humorous way.
Is there a correlation between coffee consumption and happiness? After all, Psychology Today points us towards some interesting studies that suggest coffee, such a prevalent, common drink in today’s world, can act as antidepressant.
What about COVID-19 infection rates? As the CDC describes, mental health issues have been on the rise over the past year.
With one element that contributes to happiness, and another that causes stress, can we establish some meaningful correlation to cheerfulness and positivity?
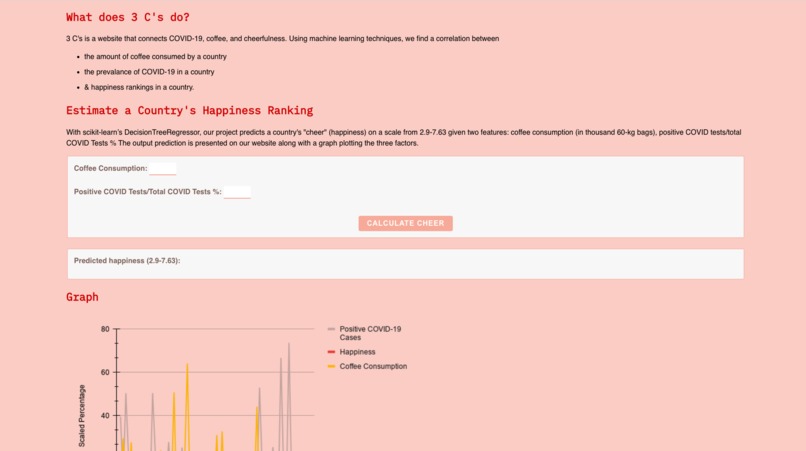
What it does
With scikit-learn’s DecisionTreeRegressor, our project predicts a country's "cheer" (happiness) on a scale from 2.9-7.63 given two features: coffee consumption (in thousand 60-kg bags), positive COVID tests/total COVID Tests %
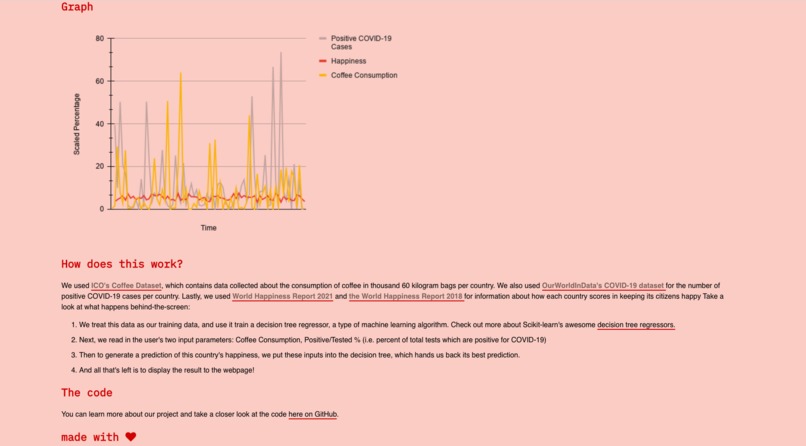
Special thanks to the open-source datasets we used: ICO's Coffee Dataset for the consumption of coffee (in thousand 60 kilogram bags) per country, OurWorldInData's COVID-19 dataset for the number of positive COVID-19 cases per country (% positive/total tested), the World Happiness Report 2018 for information about how each country scores in keeping its citizens happy on a scale of 2.9-7.63, and the World Happiness Report 2021 which does the same on a scale from 2.52-7.84.
How we built it
After gathering our data in a pandas Dataframe, we looked specifically at the domestic_consumption column in domestic-consumption.csv for countries that export coffee and the imports column in imports.csv for the countries that do not export coffee. Next, we located the Positive/Tested % column in TestsConducted_AllDates_13July2020.csv to get COVID-19 infection rates in each country. These features constituted the "x" part of our (x,y) data. For the "y" part of our (x,y) training data, we extracted the happiness score from the Score column in WorldHappiness2018_Data.csv for one decision tree, and the Ladder score column in world-happiness-report-2021.csv for an alternatively trained decision tree (we ran two separate trees, one where 2018 happiness data was the target value, see output2.txt, and another where 2021 happiness data was the target value, see output3.txt).
Next, we trained a DecisionTreeRegressor on 70% of our total data (the remaining 30% served as our testing set) with scikit-learn. Decision trees are a supervised learning algorithm, meaning that given knowledge of a country’s coffee consumption and the COVID-19 infection rate, we can predict its “cheer” score. Furthermore, we tried averaging the accuracy of multiple decision trees (bagging) and constructing a series of trees that build upon the previous tree’s weaknesses (boosting), ensemble methods known as RandomForestRegressor and GradientBoostingRegressor respectively, as well, however, these did improve accuracy significantly.
Challenges we ran into
Although our team is well-versed in Python, we have limited experience applying these skills with real-world datasets and we are especially unfamiliar with how to drop duplicate values and combine different datasets (from the many different source .csv’s we have) into a final dataset in pandas Dataframes.
Additionally, while we originally tried to host our website on Glitch, this made it difficult to connect our Python-based decision trees to our JavaScript-based Express application (which is why we switched to hosting the application on our local computers).
Unfortunately, another challenge was reconciling 2021 world happiness and COVID-19 infection data with outdated coffee consumption data from 2018. This is why we tried using the 2018 world happiness data as well, but such a switch did not make a difference.
Accomplishments that we're proud of
We applied the skills we learned in classroom settings in a real-world context. Not only did we actively search for and find reliable data, we also creatively analyzed that data. By taking initiative for our own learning, we developed critical thinking and problem solving skills that will help us continue to create technology in the future.
What we learned
By designing and developing this website, we also refined our programming skills and learned new techniques. In particular, we learned how to use DecisionTreeRegressors on real-world data and create a meaningful website for social good, because who doesn’t need a good laugh every once in a while? ;)
What's next for 3C’s
Since 3C’s does not have a direct social impact and is only meant for humorous purposes, most of its content cannot be used. However, the framework, including the machine learning techniques and webpage can be repurposed for other datasets that have a more meaningful impact. For example, the DecisionTreeRegressor can be trained on data that shows where the most COVID-19 cases are, informing government and medical officials of where to allocate the most resources. Another implementation of this overall framework is using it to determine how different factors, such as precipitation or distance, impact drivers’ mental fatigue. As a result, 3C’s is a website that has a wide array of future applications that can have a positive impact on the greater community.
Built With
- ajax
- css
- decisiontreeregressor
- hbs
- html
- javascript
- machine-learning
- pandas
- python
- scikit-learn

Log in or sign up for Devpost to join the conversation.